What the Heck is OAuth?
There’s a lot of confusion around what OAuth actually is.
Some people think OAuth is a login flow (like when you sign into an application with Google Login), and some people think of OAuth as a “security thing”, and don’t really know much more than that.
I’m going to show you what OAuth is, explain how it works, and hopefully leave you with a sense of how and where OAuth can benefit your application.
What Is OAuth?
To begin at a high level, OAuth is not an API or a service: it’s an open standard for authorization and anyone can implement it.
More specifically, OAuth is a standard that apps can use to provide client applications with “secure delegated access”. OAuth works over HTTPS and authorizes devices, APIs, servers, and applications with access tokens rather than credentials.
There are two versions of OAuth: OAuth 1.0a and OAuth 2.0. These specifications are completely different from one another, and cannot be used together: there is no backwards compatibility between them.
Which one is more popular? Great question! Nowadays, OAuth 2.0 is the most widely used form of OAuth. So from now on, whenever I say “OAuth”, I’m talking about OAuth 2.0 – as it’s most likely what you’ll be using.
Why OAuth?
OAuth was created as a response to the direct authentication pattern. This pattern was made famous by HTTP Basic Authentication, where the user is prompted for a username and password. Basic Authentication is still used as a primitive form of API authentication for server-side applications: instead of sending a username and password to the server with each request, the user sends an API key ID and secret. Before OAuth, sites would prompt you to enter your username and password directly into a form and they would login to your data (e.g. your Gmail account) as you. This is often called the password anti-pattern.
To create a better system for the web, federated identity was created for single sign-on (SSO). In this scenario, an end user talks to their identity provider, and the identity provider generates a cryptographically signed token which it hands off to the application to authenticate the user. The application trusts the identity provider. As long as that trust relationship works with the signed assertion, you’re good to go. The diagram below shows how this works.
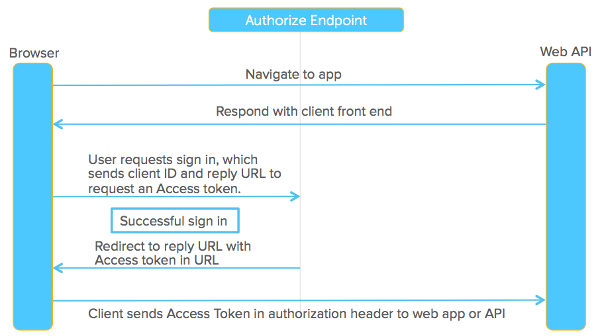
Federated identity was made famous by SAML 2.0, an OASIS Standard released on March 15, 2005. It’s a large spec but the main two components are its authentication request protocol (aka Web SSO) and the way it packages identity attributes and signs them, called SAML assertions. Okta does this with its SSO chiclets. We send a message, we sign the assertion, inside the assertion it says who the user is, and that it came from Okta. Slap a digital signature on it and you’re good to go.
SAML
SAML is basically a session cookie in your browser that gives you access to webapps. It’s limited in the kinds of device profiles and scenarios you might want to do outside of a web browser.
When SAML 2.0 was launched in 2005, it made sense. However, a lot has changed since then. Now we have modern web and native application development platforms. There are Single Page Applications (SPAs) like Gmail/Google Inbox, Facebook, and Twitter. They have different behaviors than your traditional web application, because they make AJAX (background HTTP calls) to APIs. Mobile phones make API calls too, as do TVs, gaming consoles, and IoT devices. SAML SSO isn’t particularly good at any of this.
OAuth and APIs
A lot has changed with the way we build APIs too. In 2005, people were invested in WS-* for building web services. Now, most developers have moved to REST and stateless APIs. REST is, in a nutshell, HTTP commands pushing JSON packets over the network.
Developers build a lot of APIs. The API Economy is a common buzzword you might hear in boardrooms today. Companies need to protect their REST APIs in a way that allows many devices to access them. In the old days, you’d enter your username/password directory and the app would login directly as you. This gave rise to the delegated authorization problem.
“How can I allow an app to access my data without necessarily giving it my password?”
If you’ve ever seen one of the dialogs below, that’s what we’re talking about. This is an application asking if it can access data on your behalf.
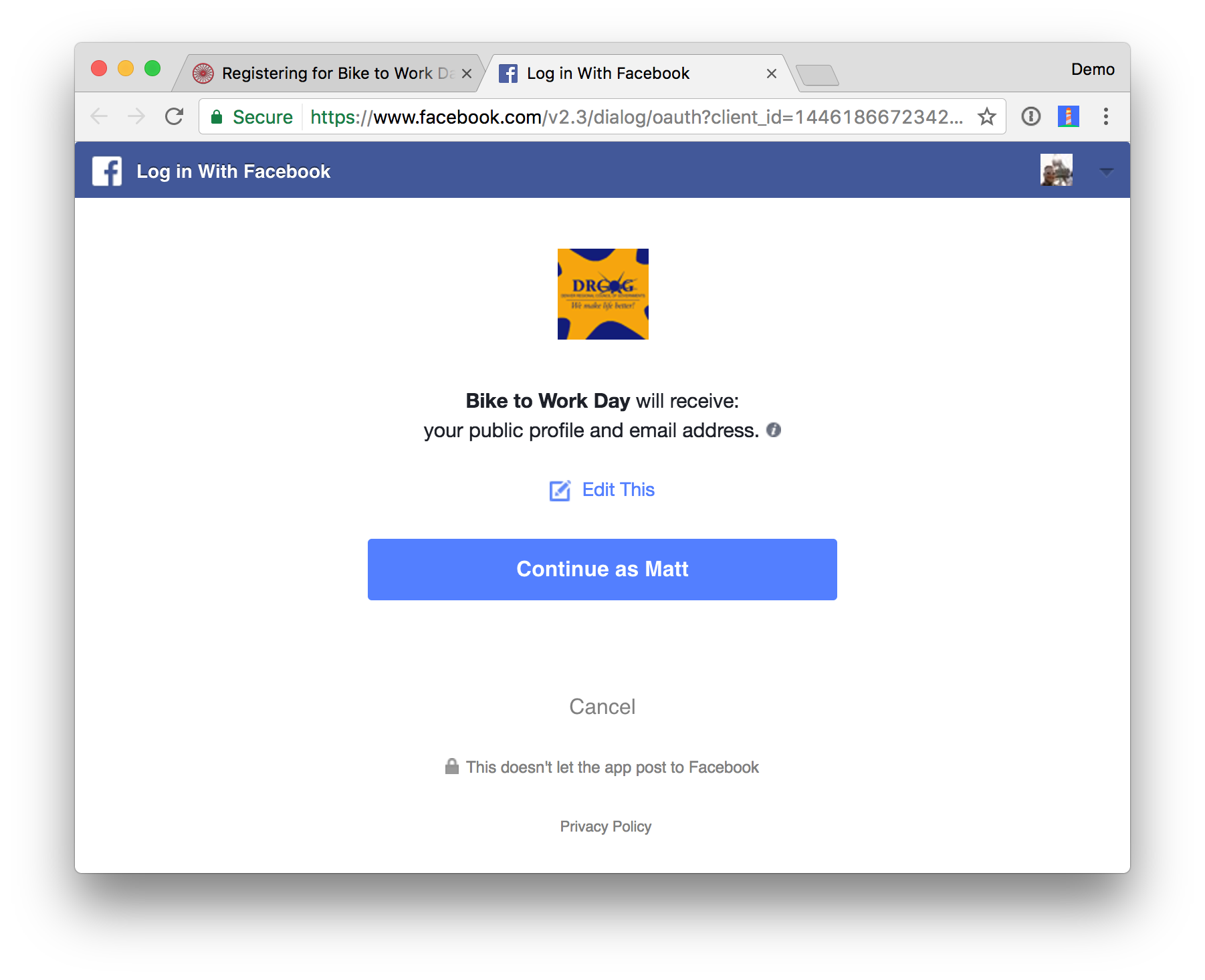
This is OAuth.
OAuth is a delegated authorization framework for REST/APIs. It enables apps to obtain limited access (scopes) to a user’s data without giving away a user’s password. It decouples authentication from authorization and supports multiple use cases addressing different device capabilities. It supports server-to-server apps, browser-based apps, mobile/native apps, and consoles/TVs.
You can think of this like hotel key cards, but for apps. If you have a hotel key card, you can get access to your room. How do you get a hotel key card? You have to do an authentication process at the front desk to get it. After authenticating and obtaining the key card, you can access resources across the hotel.
To break it down simply, OAuth is where:
- App requests authorization from User
- User authorizes App and delivers proof
- App presents proof of authorization to server to get a Token
- Token is restricted to only access what the User authorized for the specific App
OAuth Central Components
OAuth is built on the following central components:
- Scopes and Consent
- Actors
- Clients
- Tokens
- Authorization Server
- Flows
OAuth Scopes
Scopes are what you see on the authorization screens when an app requests permissions. They’re bundles of permissions asked for by the client when requesting a token. These are coded by the application developer when writing the application.
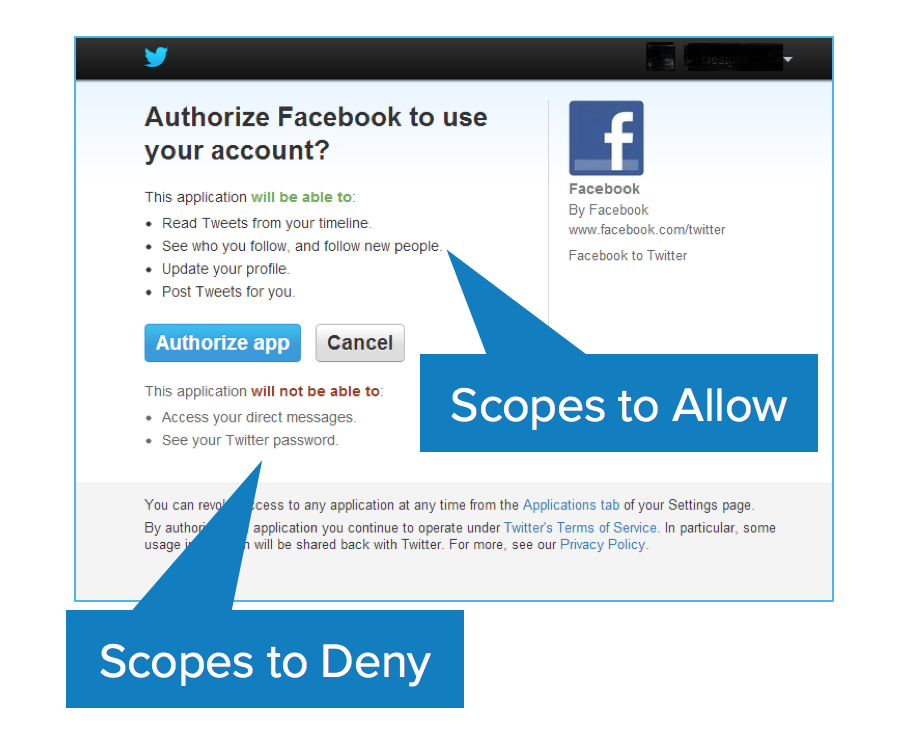
Scopes decouple authorization policy decisions from enforcement. This is the first key aspect of OAuth. The permissions are front and center. They’re not hidden behind the app layer that you have to reverse engineer. They’re often listed in the API docs: here are the scopes that this app requires.
You have to capture this consent. This is called trusting on first use. It’s a pretty significant user experience change on the web. Most people before OAuth were just used to name and password dialog boxes. Now you have this new screen that comes up and you have to train users to use. Retraining the internet population is difficult. There are all kinds of users from the tech-savvy young folk to grandparents that aren’t familiar with this flow. It’s a new concept on the web that’s now front and center. Now you have to authorize and bring consent.
The consent can vary based on the application. It can be a time-sensitive range (day, weeks, months), but not all platforms allow you to choose the duration. One thing to watch for when you consent is that the app can do stuff on your behalf - e.g. LinkedIn spamming everyone in your network.
OAuth is an internet-scale solution because it’s per application. You often have the ability to log in to a dashboard to see what applications you’ve given access to and to revoke consent.
OAuth Actors
The actors in OAuth flows are as follows:
- Resource Owner: owns the data in the resource server. For example, I’m the Resource Owner of my Facebook profile.
- Resource Server: The API which stores data the application wants to access
- Client: the application that wants to access your data
- Authorization Server: The main engine of OAuth
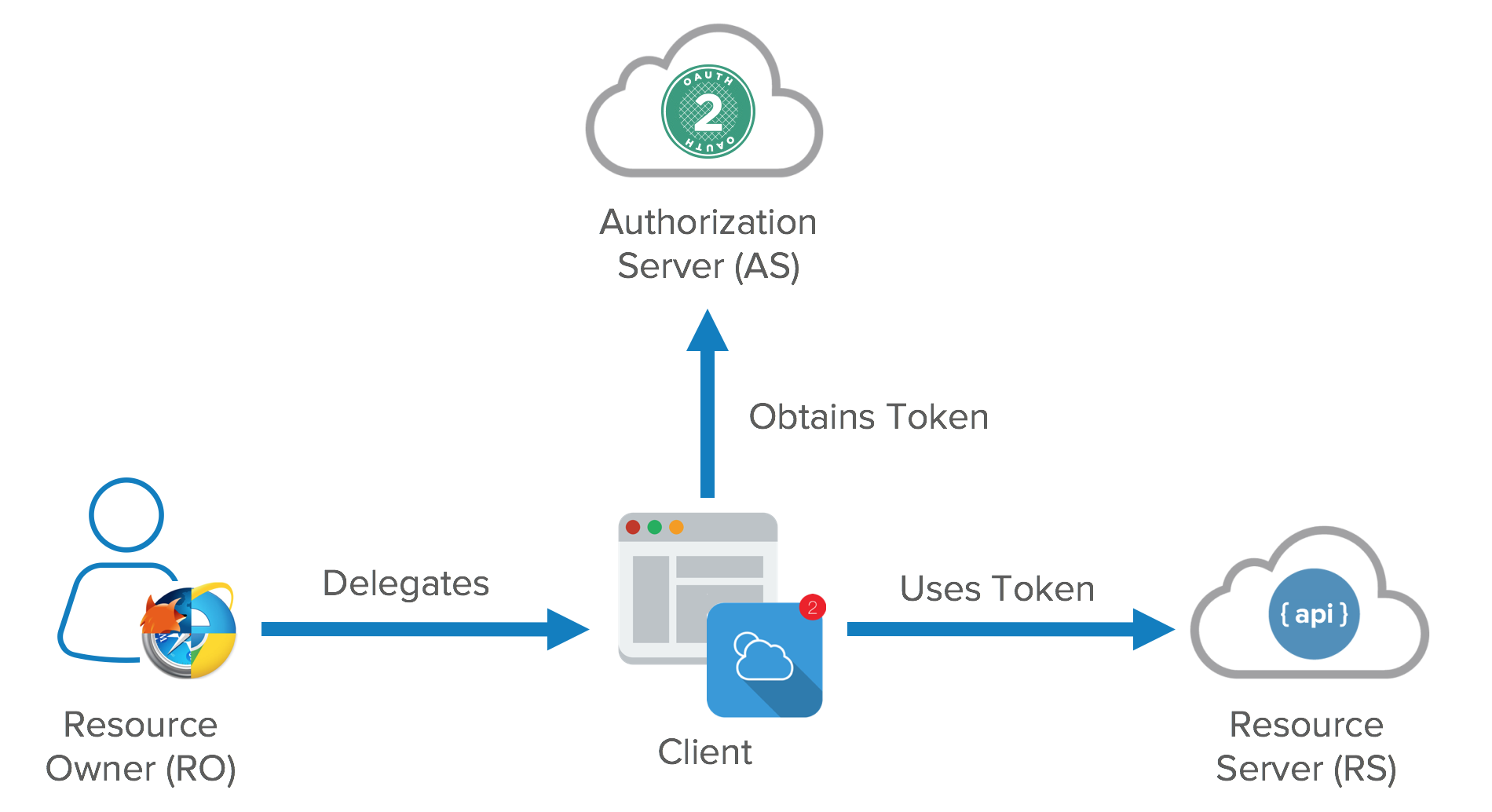
The resource owner is a role that can change with different credentials. It can be an end user, but it can also be a company.
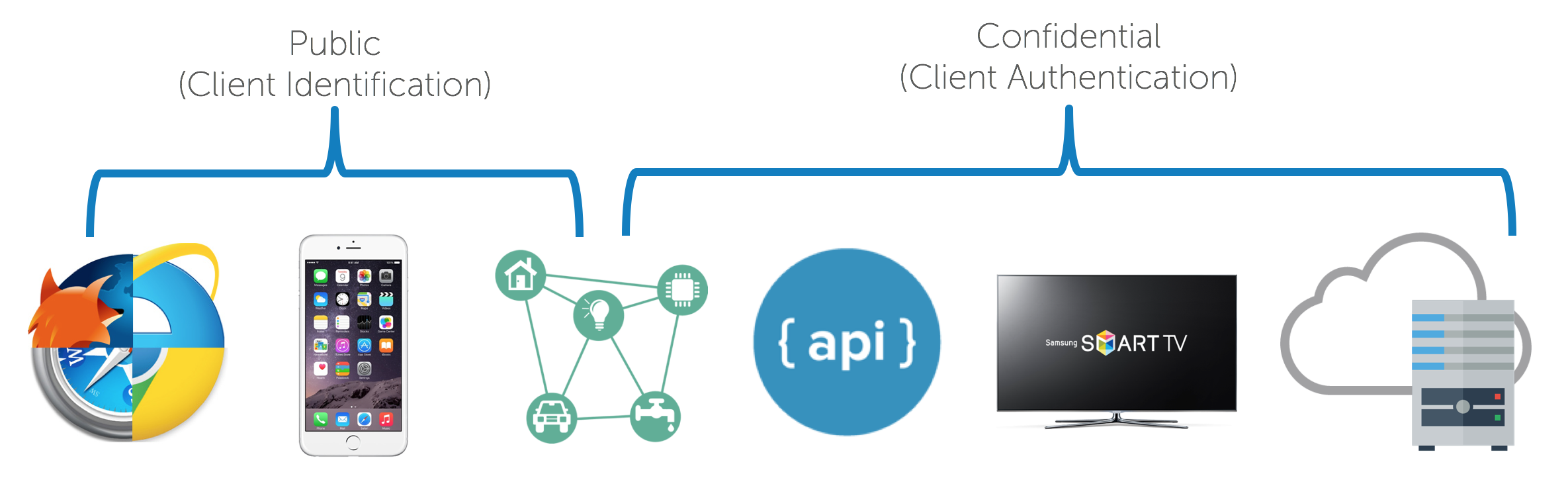
Clients can be public and confidential. There is a significant distinction between the two in OAuth nomenclature. Confidential clients can be trusted to store a secret. They’re not running on a desktop or distributed through an app store. People can’t reverse engineer them and get the secret key. They’re running in a protected area where end users can’t access them.
Public clients are browsers, mobile apps, and IoT devices.
Client registration is also a key component of OAuth. It’s like the DMV of OAuth. You need to get a license plate for your application. This is how your app’s logo shows up in an authorization dialog.
OAuth Tokens
Access tokens are the token the client uses to access the Resource Server (API). They’re meant to be short-lived. Think of them in hours and minutes, not days and month. You don’t need a confidential client to get an access token. You can get access tokens with public clients. They’re designed to optimize for internet scale problems. Because these tokens can be short lived and scale out, they can’t be revoked, you just have to wait for them to time out.
The other token is the refresh token. This is much longer-lived; days, months, years. This can be used to get new tokens. To get a refresh token, applications typically require confidential clients with authentication.
Refresh tokens can be revoked. When revoking an application’s access in a dashboard, you’re killing its refresh token. This gives you the ability to force the clients to rotate secrets. What you’re doing is you’re using your refresh token to get new access tokens and the access tokens are going over the wire to hit all the API resources. Each time you refresh your access token you get a new cryptographically signed token. Key rotation is built into the system.
The OAuth spec doesn’t define what a token is. It can be in whatever format you want. Usually though, you want these tokens to be JSON Web Tokens (a standard). In a nutshell, a JWT (pronounced “jot”) is a secure and trustworthy standard for token authentication. JWTs allow you to digitally sign information (referred to as claims) with a signature and can be verified at a later time with a secret signing key. To learn more about JWTs, see A Beginner’s Guide to JWTs in Java.
Tokens are retrieved from endpoints on the authorization server. The two main endpoints are the authorize endpoint and the token endpoint. They’re separated for different use cases. The authorize endpoint is where you go to get consent and authorization from the user. This returns an authorization grant that says the user has consented to it. Then the authorization is passed to the token endpoint. The token endpoint processes the grant and says “great, here’s your refresh token and your access token”.
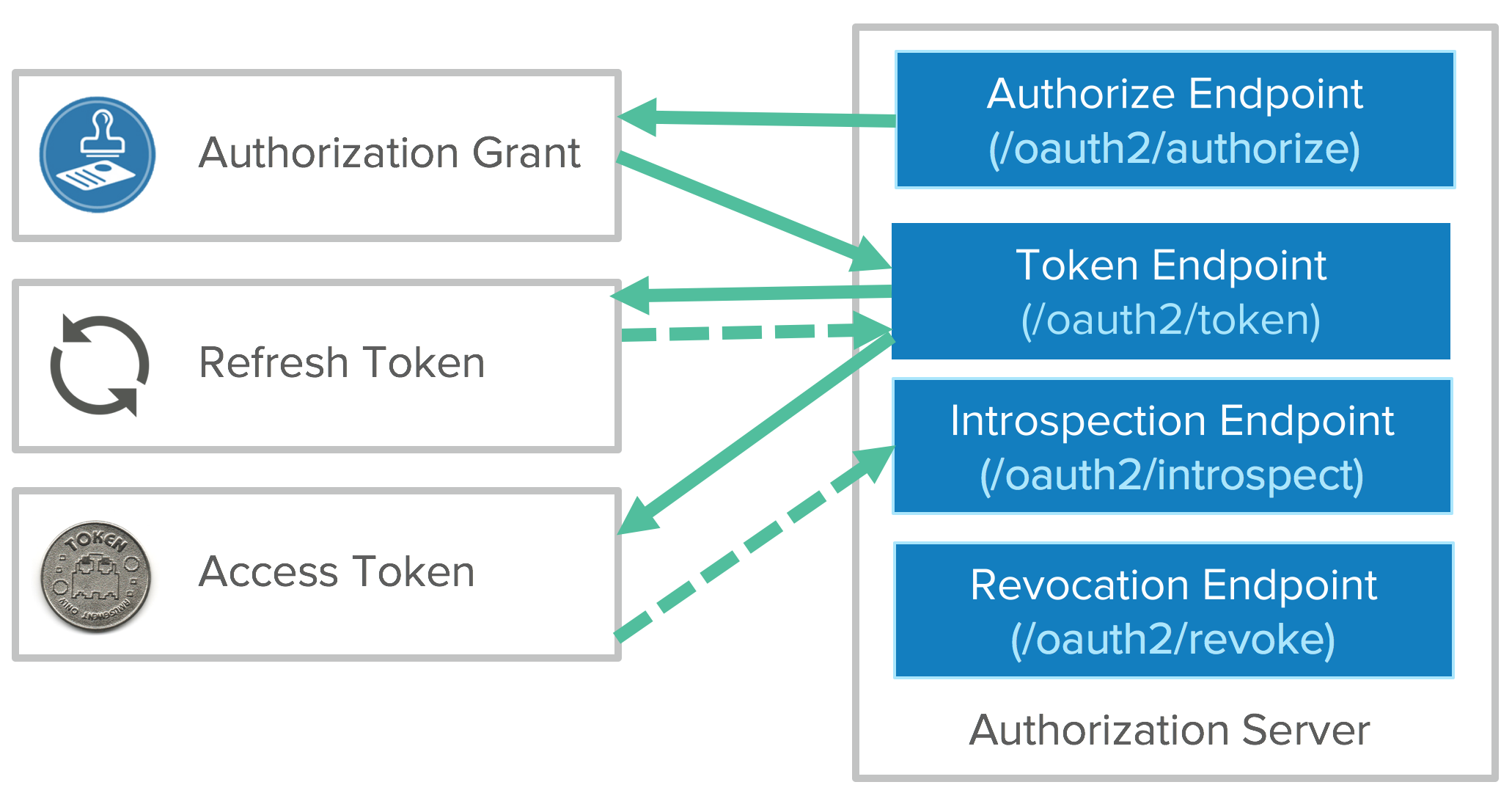
You can use the access token to get access to APIs. Once it expires, you’ll have to go back to the token endpoint with the refresh token to get a new access token.
The downside is this causes a lot of developer friction. One of the biggest pain points of OAuth for developers is you having to manage the refresh tokens. You push state management onto each client developer. You get the benefits of key rotation, but you’ve just created a lot of pain for developers. That’s why developers love API keys. They can just copy/paste them, slap them in a text file, and be done with them. API keys are very convenient for the developer, but very bad for security.
There’s a pay to play problem here. Getting developers to do OAuth flows increases security, but there’s more friction. There are opportunities for toolkits and platforms to simplify things and help with token management. Luckily, OAuth is pretty mature these days, and chances are your favorite language or framework has tools available to simplify things.
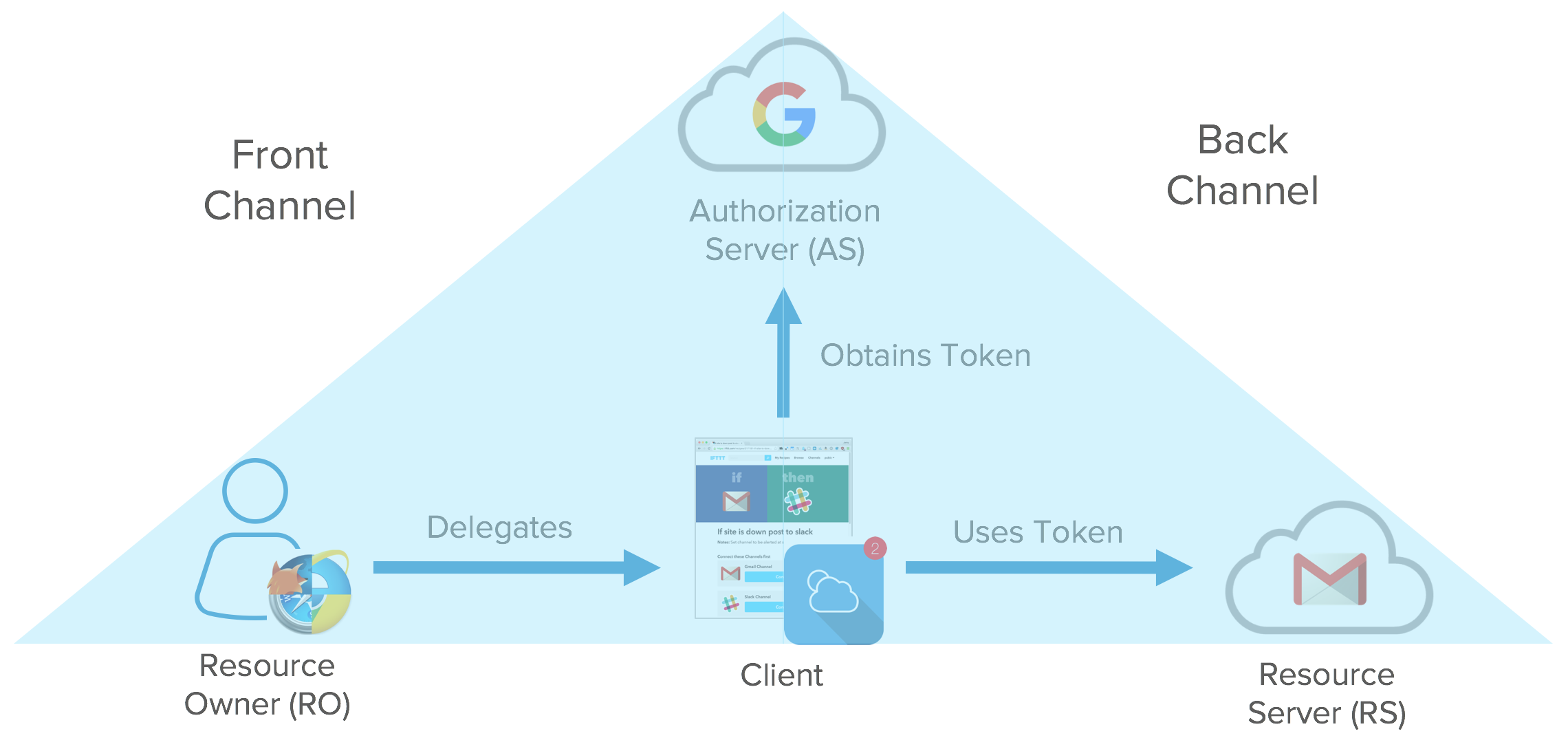
We’ve talked a bit about the client types, the token types, and the endpoints of the authorization server and how we can pass that to a resource server. I mentioned two different flows: getting the authorization and getting the tokens. Those don’t have to happen on the same channel. The front channel is what goes over the browser. The browser redirected the user to the authorization server, the user gave consent. This happens on the user’s browser. Once the user takes that authorization grant and hands that to the application, the client application no longer needs to use the browser to complete the OAuth flow to get the tokens.
The tokens are meant to be consumed by the client application so it can access resources on your behalf. We call that the back channel. The back channel is an HTTP call directly from the client application to the resource server to exchange the authorization grant for tokens. These channels are used for different flows depending on what device capabilities you have.
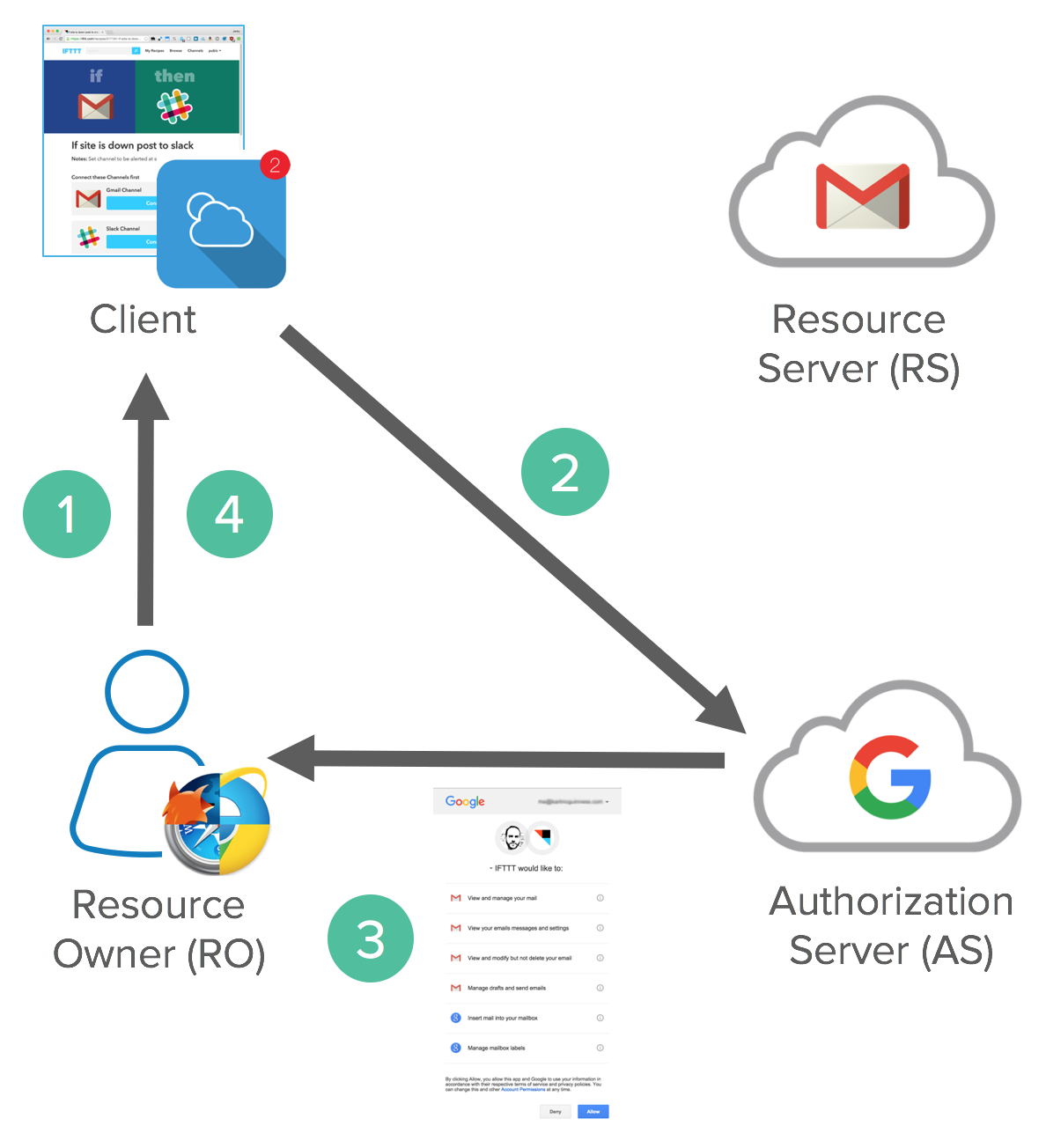
For example, a Front Channel Flow where you authorize via user agent might look as follows:
- Resource Owner starts flow to delegate access to protected resource
- Client sends authorization request with desired scopes via browser redirect to the Authorize Endpoint on the Authorization Server
- Authorization Server returns a consent dialog saying “do you allow this application to have access to these scopes?” Of course, you’ll need to authenticate to the application, so if you’re not authenticated to your Resource Server, it’ll ask you to login. If you already have a cached session cookie, you’ll just see the consent dialog box. View the consent dialog, and agree.
- The authorization grant is passed back to the application via browser redirect. This all happens on the front channel.
There’s also a variance in this flow called the implicit flow. We’ll get to that in a minute.
This is what it looks like on the wire.
| Request |
GET https://accounts.google.com/o/oauth2/auth?scope=gmail.insert gmail.send &redirect_uri=https://app.example.com/oauth2/callback &response_type=code&client_id=812741506391 &state=af0ifjsldkj This is a GET request with a bunch of query params (not URL-encoded for example purposes). Scopes are from Gmail's API. The redirect_uri is the URL of the client application that the authorization grant should be returned to. This should match the value from the client registration process (at the DMV). You don't want the authorization being bounced back to a foreign application. Response type varies the OAuth flows. Client ID is also from the registration process. State is a security flag, similar to XRSF. To learn more about XRSF, see DZone's "Cross-Site Request Forgery explained". |
| Response |
HTTP/1.1 302 Found Location: https://app.example.com/oauth2/callback? code=MsCeLvIaQm6bTrgtp7&state=af0ifjsldkj
The |
After the Front Channel is done, a Back Channel Flow happens, exchanging the authorization code for an access token.
The Client application sends an access token request to the token endpoint on the Authorization Server with confidential client credentials and client id. This process exchanges an Authorization Code Grant for an Access Token and (optionally) a Refresh Token. Client accesses a protected resource with Access Token.
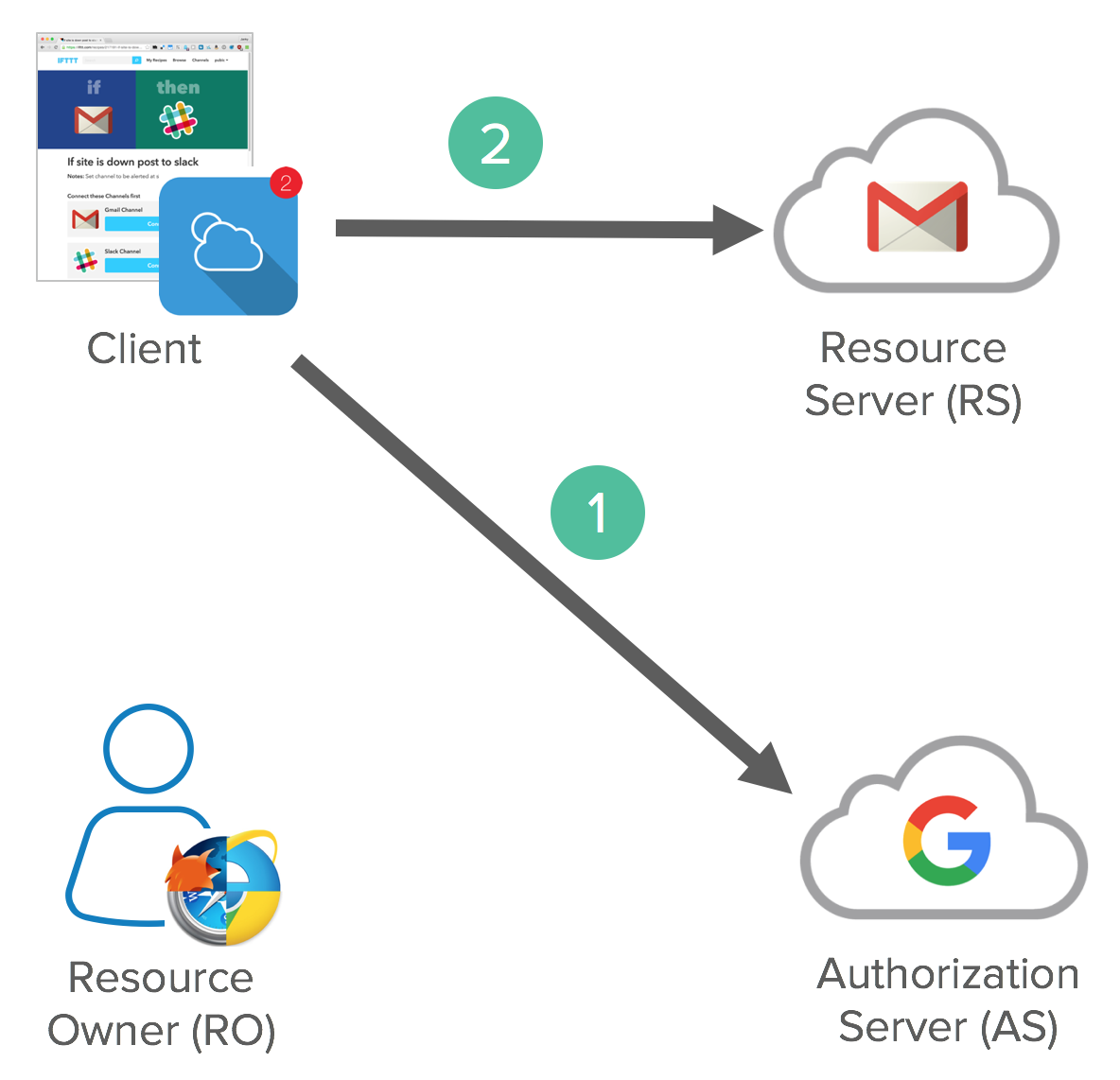
Below is how this looks in raw HTTP.
| Request |
POST /oauth2/v3/token HTTP/1.1
Host: www.googleapis.com
Content-Type: application/x-www-form-urlencoded
code=MsCeLvIaQm6bTrgtp7&client_id=812741506391&client_secret={client_secret}&redirect_uri=https://app.example.com/oauth2/callback&grant_type=authorization_code
The grant_type is the extensibility part of OAuth. It's an authorization code from a precomputed perspective. It opens up the flexibility to have different ways to describe these grants. This is the most common type of OAuth flow. |
| Response |
{
"access_token": "2YotnFZFEjr1zCsicMWpAA",
"token_type": "Bearer",
"expires_in": 3600,
"refresh_token": "tGzv3JOkF0XG5Qx2TlKWIA"
}
The response is JSON. You can be reactive or proactive in using tokens. Proactive is to have a timer in your client. Reactive is to catch an error and attempt to get a new token then. |
Once you have an access token, you can use the access token in an Authentication header (using the token_type as a prefix) to make protected resource requests.
curl -H "Authorization: Bearer 2YotnFZFEjr1zCsicMWpAA" \
https://www.googleapis.com/gmail/v1/users/1444587525/messages
So now you have a front channel, a back channel, different endpoints, and different clients. You have to mix and match these for different use cases. This up-levels the complexity of OAuth and it can get confusing.
OAuth Flows
The very first flow is what we call the Implicit Flow. The reason it’s called the implicit flow is because all the communication is happening through the browser. There is no backend server redeeming the authorization grant for an access token. An SPA is a good example of this flow’s use case. This flow is also called 2 Legged OAuth.
Implicit flow is optimized for browser-only public clients. An access token is returned directly from the authorization request (front channel only). It typically does not support refresh tokens. It assumes the Resource Owner and Public Client are on the same device. Since everything happens on the browser, it’s the most vulnerable to security threats.
The gold standard is the Authorization Code Flow, aka 3 Legged, that uses both the front channel and the back channel. This is what we’ve been talking about the most in this article. The front channel flow is used by the client application to obtain an authorization code grant. The back channel is used by the client application to exchange the authorization code grant for an access token (and optionally a refresh token). It assumes the Resource Owner and Client Application are on separate devices. It’s the most secure flow because you can authenticate the client to redeem the authorization grant, and tokens are never passed through a user-agent. There’s not just Implicit and Authorization Code flows, there are additional flows you can do with OAuth. Again, OAuth is more of a framework.
For server-to-server scenarios, you might want to use a Client Credential Flow. In this scenario, the client application is a confidential client that’s acting on its own, not on behalf of the user. It’s more of a service account type of scenario. All you need is the client’s credentials to do the whole flow. It’s a back channel only flow to obtain an access token using the client’s credentials. It supports shared secrets or assertions as client credentials signed with either symmetric or asymmetric keys.
Symmetric-key algorithms are cryptographic algorithms that allow you to decrypt anything, as long as you have the password. This is often found when securing PDFs or .zip files.
Public key cryptography, or asymmetric cryptography, is any cryptographic system that uses pairs of keys: public keys and private keys. Public keys can be read by anyone, private keys are sacred to the owner. This allows data to be secure without the need to share a password.
There’s also a legacy mode called Resource Owner Password Flow. This is very similar to the direct authentication with username and password scenario and is not recommended. It’s a legacy grant type for native username/password apps such as desktop applications. In this flow, you send the client application a username and password and it returns an access token from the Authorization Server. It typically does not support refresh tokens and it assumes the Resource Owner and Public Client are on the same device. For when you have an API that only wants to speak OAuth, but you have old-school clients to deal with.
A more recent addition to OAuth is the Assertion Flow, which is similar to the client credential flow. This was added to open up the idea of federation. This flow allows an Authorization Server to trust authorization grants from third parties such as SAML IdP. The Authorization Server trusts the Identity Provider. The assertion is used to obtain an access token from the token endpoint. This is great for companies that have invested in SAML or SAML-related technologies and allow them to integrate with OAuth. Because SAML assertions are short-lived, there are no refresh tokens in this flow and you have to keep retrieving access tokens every time the assertion expires.
Not in the OAuth spec, is a Device Flow. There’s no web browser, just a controller for something like a TV. A user code is returned from an authorization request that must be redeemed by visiting a URL on a device with a browser to authorize. A back channel flow is used by the client application to poll for authorization approval for an access token and optionally a refresh token. Also popular for CLI clients.
We’ve covered six different flows using the different actors and token types. They’re necessary because of the capabilities of the clients, how we needed to get consent from the client, who is making consent, and that adds a lot of complexity to OAuth.
When people ask if you support OAuth, you have to clarify what they’re asking for. Are they asking if you support all six flows, or just the main ones? There’s a lot of granularity available between all the different flows.
Security and the Enterprise
There’s a large surface area with OAuth. With Implicit Flow, there’s lots of redirects and lots of room for errors. There’s been a lot of people trying to exploit OAuth between applications and it’s easy to do if you don’t follow recommended Web Security 101 guidelines. For example:
- Always use CSRF token with the
stateparameter to ensure flow integrity - Always whitelist redirect URIs to ensure proper URI validations
- Bind the same client to authorization grants and token requests with a client ID
- For confidential clients, make sure the client secrets aren’t leaked. Don’t put a client secret in your app that’s distributed through an App Store!
The biggest complaint about OAuth in general comes from Security people. It’s regarding the Bearer tokens and that they can be passed just like session cookies. You can pass it around and you’re good to go, it’s not cryptographically bound to the user. Using JWTs helps because they can’t be tampered with. However, in the end, a JWT is just a string of characters so they can easily be copied and used in an Authorization header.
Enterprise OAuth 2.0 Use Cases
OAuth decouples your authorization policy decisions from authentication. It enables the right blend of fine and coarse grained authorization. It can replace traditional Web Access Management (WAM) Policies. It’s also great for restricting and revoking permissions when building apps that can access specific APIs. It ensures only managed and/or compliant devices can access specific APIs. It has deep integration with identity deprovisioning workflows to revoke all tokens from a user or device. Finally, it supports federation with an identity provider.
OAuth is not an Authentication Protocol
To summarize some of the misconceptions of OAuth 2.0: it’s not backwards compatible with OAuth 1.0. It replaces signatures with HTTPS for all communication. When people talk about OAuth today, they’re talking about OAuth 2.0.
Because OAuth is an authorization framework and not a protocol, you may have interoperability issues. There are lots of variances in how teams implement OAuth and you might need custom code to integrate with vendors.
OAuth 2.0 is not an authentication protocol. It even says so in its documentation.
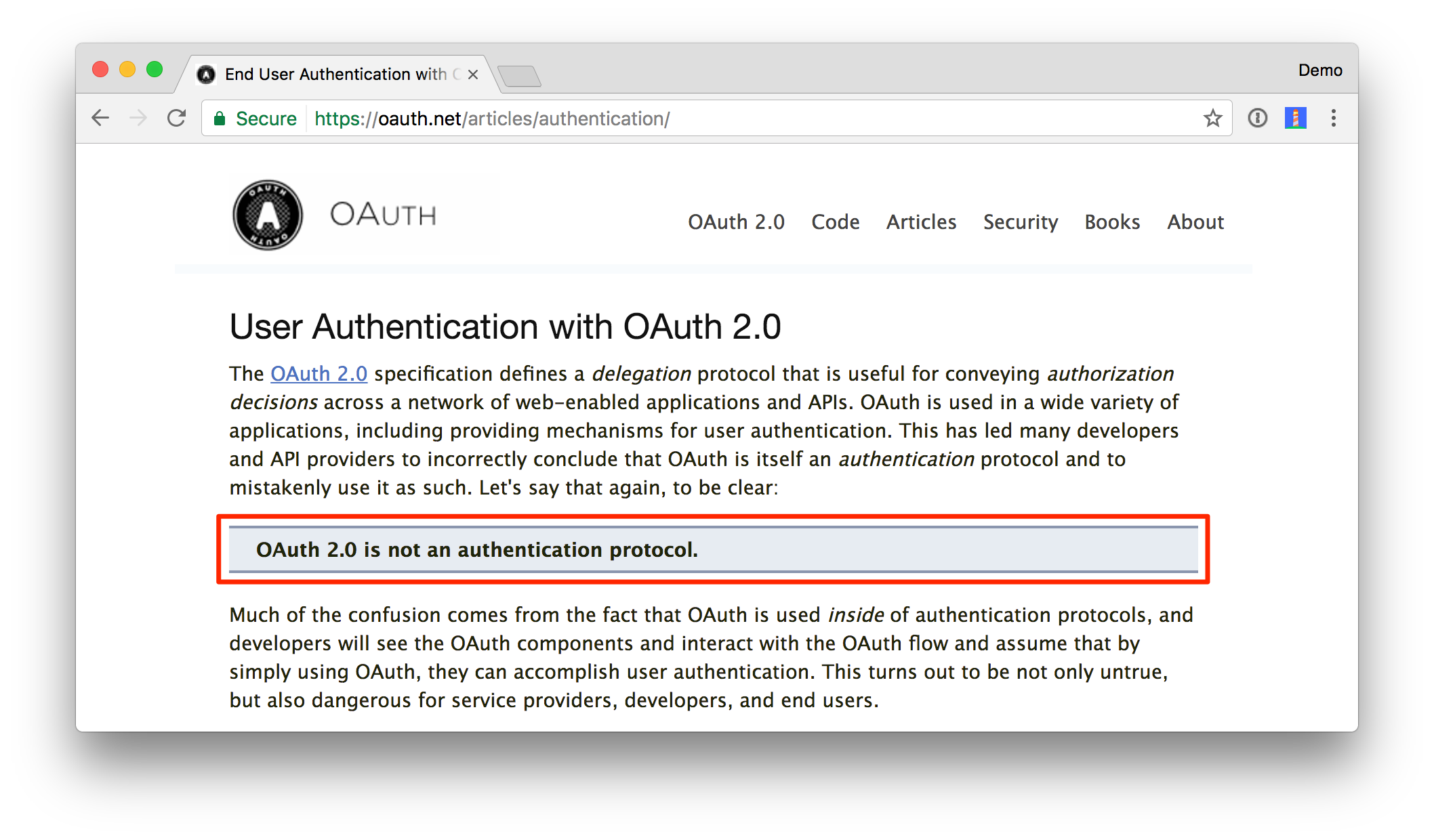
We’ve been talking about delegated authorization this whole time. It’s not about authenticating the user, and this is key. OAuth 2.0 alone says absolutely nothing about the user. You just have a token to get access to a resource.
There’s a huge number of additions that’ve happened to OAuth in the last several years. These add complexity back on top of OAuth to complete a variety of enterprise scenarios. For example, JWTs can be used as interoperable tokens that can be signed and encrypted.
Pseudo-Authentication with OAuth 2.0
Login with OAuth was made famous by Facebook Connect and Twitter. In this flow, a client accesses a /me endpoint with an access token. All it says is that the client has access to the resource with a token. People invented this fake endpoint as a way of getting back a user profile with an access token. It’s a non-standard way to get information about the user. There’s nothing in the standards that say everyone has to implement this endpoint. Access tokens are meant to be opaque. They’re meant for the API, they’re not designed to contain user information.
What you’re really trying to answer with authentication is who the user is, when did the user authenticate, and how did the user authenticate. You can typically answer these questions with SAML assertions, not with access tokens and authorization grants. That’s why we call this pseudo authentication.
Enter OpenID Connect
To solve the pseudo authentication problem, the best parts of OAuth 2.0, Facebook Connect, and SAML 2.0 were combined to create OpenID Connect. OpenID Connect (OIDC) extends OAuth 2.0 with a new signed id_token for the client and a UserInfo endpoint to fetch user attributes. Unlike SAML, OIDC provides a standard set of scopes and claims for identities. Examples include: profile, email, address, and phone.
OIDC was created to be internet scalable by making things completely dynamic. There’s no longer downloading metadata and federation like SAML requires. There’s built-in registration, discovery, and metadata for dynamic federations. You can type in your email address, then it dynamically discovers your OIDC provider, dynamically downloads the metadata, dynamically know what certs it’s going to use, and allows BYOI (Bring Your Own Identity). It supports high assurance levels and key SAML use cases for enterprises.
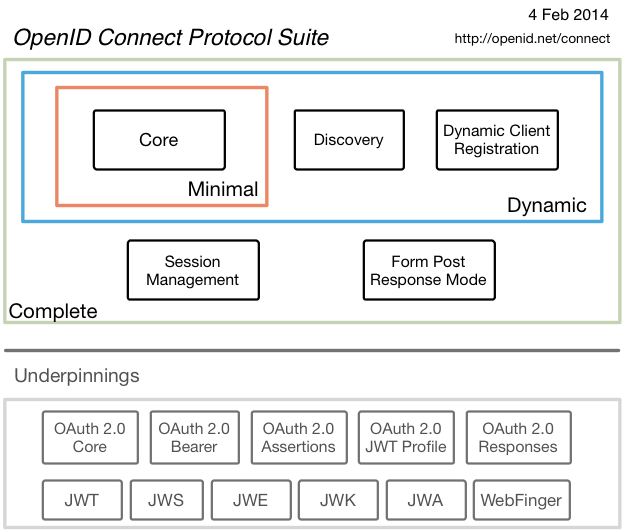
OIDC was made famous by Google and Microsoft, both big early adopters. Okta has made a big investment in OIDC as well.
All that changes in the initial request is it contains standard scopes (like openid and email):
| Request |
GET https://accounts.google.com/o/oauth2/auth? scope=openid email& redirect_uri=https://app.example.com/oauth2/callback& response_type=code& client_id=812741506391& state=af0ifjsldkj |
| Response |
HTTP/1.1 302 Found Location: https://app.example.com/oauth2/callback? code=MsCeLvIaQm6bTrgtp7&state=af0ifjsldkj
The |
And the authorization grant for tokens response contains an ID token.
| Request |
POST /oauth2/v3/token HTTP/1.1
Host: www.googleapis.com
Content-Type: application/x-www-form-urlencoded
code=MsCeLvIaQm6bTrgtp7&client_id=812741506391&
client_secret={client_secret}&
redirect_uri=https://app.example.com/oauth2/callback&
grant_type=authorization_code
|
| Response |
{
"access_token": "2YotnFZFEjr1zCsicMWpAA",
"token_type": "Bearer",
"expires_in": 3600,
"refresh_token": "tGzv3JOkF0XG5Qx2TlKWIA",
"id_token": "eyJhbGciOiJSUzI1NiIsImtpZCI6IjFlOWdkazcifQ..."
}
|
You can see this is layered nicely on top of OAuth to give back an ID token as a structured token. An ID token is a JSON Web Token (JWT). A JWT (aka “jot”) is much smaller than a giant XML-based SAML assertion and can be efficiently passed around between different devices. A JWT has three parts: a header, a body, and a signature. The header says what algorithm was used to sign it, the claims are in the body, and its signed in the signature.
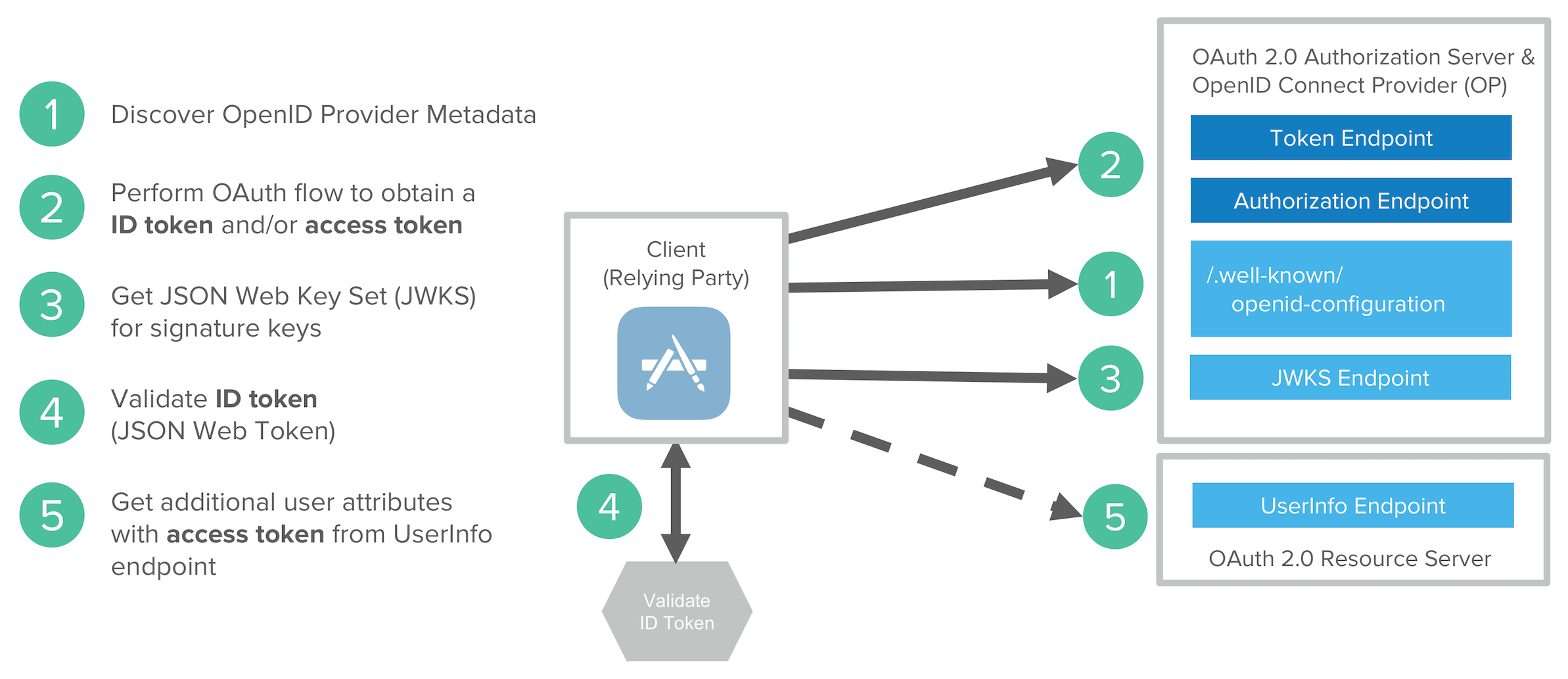
An Open ID Connect flow involves the following steps:
- Discover OIDC metadata
- Perform OAuth flow to obtain id token and access token
- Get JWT signature keys and optionally dynamically register the Client application
- Validate JWT ID token locally based on built-in dates and signature
- Get additional user attributes as needed with access token
OAuth + Okta
Okta is best known for its single-sign on services that allow you to seamlessly authenticate to the applications you use on a daily basis. But did you know Okta also has an awesome developer platform? Secure single sign-on often uses SAML as the protocol of choice, but Okta also provides several other options, including a Sign-in Widget, Auth SDK (a JavaScript-based library), Social Login, and an Authentication API for any client. If you’re interested in learning about Okta straight from the source, you should attend Oktane17 in late August. There’s a track dedicated to app development.
See Okta’s OIDC/OAuth 2.0 API for specific information on how we support OAuth.
SAML is implemented by Okta with its SSO chiclets. If you’re an Okta customer, like me, you likely interact with most apps using something like https://okta.okta.com/app/UserHome. When you click on a chiclet, we send a message, we sign the assertion, inside the assertion it says who the user is, and that it came from Okta. Slap on a digital signature on it and you’re good to go.
If you’d rather watch a video to learn about OAuth, please see the presentation below from Nate Barbettini, Product Manager at Okta.
OAuth 2.0 Summary
OAuth 2.0 is an authorization framework for delegated access to APIs. It involves clients that request scopes that Resource Owners authorize/give consent to. Authorization grants are exchanged for access tokens and refresh tokens (depending on flow). There are multiple flows to address varying client and authorization scenarios. JWTs can be used for structured tokens between Authorization Servers and Resource Servers.
OAuth has a very large security surface area. Make sure to use a secure toolkit and validate all inputs!
OAuth is not an authentication protocol. OpenID Connect extends OAuth 2.0 for authentication scenarios and is often called “SAML with curly-braces”. If you’re looking to dive even deeper into OAuth 2.0, I recommend you check out OAuth.com, take Okta’s Auth SDK for a spin, and try out the OAuth flows for yourself.
If you’d like to learn more about OAuth and OIDC, we suggest the following posts:
- What is the OAuth 2.0 Authorization Code Grant Type?
- What is the OAuth 2.0 Implicit Grant Type?
- What is the OAuth 2.0 Password Grant Type?
- Is the OAuth 2.0 Implicit Flow Dead?
- Identity, Claims, & Tokens – An OpenID Connect Primer, Part 1 of 3
- OIDC in Action – An OpenID Connect Primer, Part 2 of 3
- What’s in a Token? – An OpenID Connect Primer, Part 3 of 3
If you’re passionate about OAuth 2.0 and OIDC like we are, give us a follow on Twitter or check out our new security site where we’re publishing in-depth articles on security topics.
Matt Raible is a well-known figure in the Java community and has been building web applications for most of his adult life. For over 20 years, he has helped developers learn and adopt open source frameworks and use them effectively. He's a web developer, Java Champion, and Developer Advocate at Okta. Matt has been a speaker at many conferences worldwide, including Devnexus, Devoxx Belgium, Devoxx France, Jfokus, and JavaOne. He is the author of The Angular Mini-Book, The JHipster Mini-Book, Spring Live, and contributed to Pro JSP. He is a frequent contributor to open source and a member of the JHipster development team. You can find him online @mraible and raibledesigns.com.
Okta Developer Blog Comment Policy
We welcome relevant and respectful comments. Off-topic comments may be removed.