Build a Secure Spring Data JPA Resource Server

In this tutorial, you’re going to use Spring Boot and Spring Data to build a fully functioning web service with ridiculously little effort. You’re also going to use Okta to secure the web service using professional, standards-compliant OIDC JWT authentication. All of this will be bootstrapped by the Okta CLI.
Before you get started on the actual application, however, let’s take a look at Spring Data for a moment.
Table of Contents
- What is Spring Data?
- Spring Data JPA Overview
- Bootstrap a Spring Data JPA Project with the Okta CLI
- Create a Dinosaur Domain Model
- Create a Spring Data Repository
- Test Your Spring Data JPA-Powered REST API
- Implement an OAuth 2.0 Resource Server
- Generate an Access Token JWT
- Access Your API with an OAuth 2.0 Bearer Token
- Learn More About Spring Data and Spring Boot
Note: In May 2025, the Okta Integrator Free Plan replaced Okta Developer Edition Accounts, and the Okta CLI was deprecated.
We preserved this post for reference, but the instructions no longer work exactly as written. Replace the Okta CLI commands by manually configuring Okta following the instructions in our Developer Documentation.
What is Spring Data?
Spring Data is a behemoth. Spring calls it an “umbrella” framework. It ties together a large number of different sub-projects that aim to provide a consistent programming interface for everything from SQL and Postgres, to NoSQL databases like MongoDB, Cassandra, and Redis. It also natively supports technologies such as Hibernate, JDBC, LDAP, KeyValue stores, Geode, and GemFire. Community modules add support for many other projects, such as Couchbase, DynamoDB, Elasticsearch, Neo4j, and Apache Solr. The idea is to bring all of these technologies together with a consistent and familiar (to Spring developers, anyway) interface that makes it easy to implement and maintain applications using these technologies.
In a Java web service, Spring Data can provide a number of important functions. It allows the developer to quickly and easily declare data objects or entities using simple annotated Java classes. Spring Data will automatically map the annotated Java class to an appropriate persistence structure. It also provides a repository interface that manages reading from and writing to the database using an intuitive, query-like method structure. Finally, in some cases, it will even expose the data model and repository to the web, creating a REST service.
All of this means that, as you will see, with a few simple files, you can define your data model using a Java class, seamlessly persist it to a database, and expose that data in a secure RESTful web service.
Spring Data works well with Spring Boot, providing a super-efficient way to create web applications without having to code a whole lot of configuration and boilerplate code. Using Spring Boot and Spring MVC, RESTful web services can be created in minutes with only a handful of files and a few dozen lines of code.
Spring Data also supports reactive programming (asynchronous, non-blocking). The Spring WebFlux sub-project provides the reactive web server features for Spring Boot, and when combined with the relatively new R2DBC project (for relational databases) or Reactive Repositories (for NoSQL) you can build an entirely reactive web service.
The vision behind Spring Data is that, ideally, the same data model code and business logic code could be used with a variety of databases, and that switching between them would only require changing some dependencies and the implemented repository interface. In reality, this is asking a lot of abstraction. Typically, one chooses SQL or MongoDB because of features specific to that database, features that are not shared by all other databases. Fortunately, Spring Data exposes the unique, individual features of each database. Spring Data strikes a nice balance between simplification and abstraction while preserving database-specific features and deep customization.
That’s a TON of options. Let’s narrow it down. The first decision one needs to make is what database suits the needs of the application. In this case, you’re going to use a relational database (SQL). More specifically, you’re going to use the default Hibernate in-memory database that Spring Boot and Spring Data include by default when configuring a project.
This database is great for testing, example applications, and mock-ups. It’s quick and easy because it doesn’t require setting up an external database. It doesn’t persist between sessions, which for testing and for example apps, may be exactly what you need. Also, when you decide it’s time to move to a database that’s not in-memory, all you have to do is update some dependencies and add a little configuration.
Spring Data JPA Overview
Since you’re going to be using a relational database, you’re also going to be using Spring Data JPA. JPA is the Java Persistence API. JPA is a specification that outlines how Java objects can be mapped to database tables. Historically, JPA has only supported SQL databases, however, this is changing with EclipseLink and JPA 2.2. Spring Data JPA is the implementation of this JPA specification. This technology is what will allow you to create a plain Java class with a few annotations and expect it to be seamlessly mapped to and from the database.
Prerequisites:
You’ll need to install a few things before you get started.
- Java 11: This tutorial uses Java 11. OpenJDK 11 will work just as well. You can find instructions on the OpenJDK website. You can install OpenJDK using Homebrew. Alternatively, SDKMAN is another great option for installing and managing Java versions.
- HTTPie: This is a powerful command-line HTTP request utility that you’ll use to test the WebFlux server. Install it according to the docs on their site.
- Okta CLI: You’ll use this to bootstrap your project. Follow the installation instructions on the project’s GitHub page.
You’ll need a free Okta developer account to complete this tutorial. However, the Okta CLI will walk you through the registration process or allow you to log in using your credentials.
If you would rather follow along by watching a video, check out the screencast below from our YouTube channel.
NOTE: This video puts your settings in src/main/resources/application.properties. We’ve since changed the default behavior to use spring-dotenv.
Bootstrap a Spring Data JPA Project with the Okta CLI
Open a shell and, in a reasonable parent folder location, and run the Okta CLI.
okta start spring-boot
If you haven’t used the Okta CLI before, you’ll be prompted to create an account. If you have an Okta account already, you can sign in using okta login.
You’ll see the following:
Configuring a new OIDC Application, almost done:
Created OIDC application, client-id: 0oa168nw50nxJSSmg4x7
Change the directory:
cd spring-boot
Okta configuration written to .okta.env.
Add this file to .gitignore!
Run this application with:
./mvnw spring-boot:run
At this point, you can run the app.
cd spring-boot
./mvnw spring-boot:run
Open a browser to http://localhost:8080.
CAUTION: If you get an invalid target release: 11 error, it’s likely because you’re using Java 8. This tutorial requires Java 11. Time to upgrade! 😛
If you’re already logged into Okta, you’ll be directed to a page that displays “Hello: <username>”. If not, you’ll be directed to Okta to log in via OpenID Connect (OIDC). This is the default configuration. You’re going to change this to behavior from a client login flow to a JWT-based, resource server flow.
TIP: If you’re not familiar with OpenID Connect, resource servers, and all that jazz, you might want to check out An Illustrated Guide to OAuth and OpenID Connect.
Create a new Java class that will update the security configuration. This file temporarily allows all requests, effectively disabling security. You’ll change this later in the tutorial to enable JWT authentication.
src/main/java/com/example/sample/SecurityConfiguration.java
package com.example.sample;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
@EnableWebSecurity
public class SecurityConfiguration extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests(authorizeRequests ->
authorizeRequests.antMatchers("/**").permitAll()
.anyRequest().authenticated())
.csrf().disable();
}
}
Update the SimpleRestController static inner class in the Application.java file so that it doesn’t cause an error if there is an anonymous user.
src/main/java/com/example/sample/Application.java
package com.example.sample;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.security.core.annotation.AuthenticationPrincipal;
import org.springframework.security.oauth2.core.oidc.user.OidcUser;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@RestController
static class SimpleRestController {
@GetMapping("/")
String sayHello(@AuthenticationPrincipal OidcUser oidcUser) {
return "Hello " + (oidcUser != null ? oidcUser.getFullName() : "anonymous");
}
}
}
Use Control-C to stop the running process if you haven’t already and run it again (up arrow on most good shells).
./mvnw spring-boot:run
Use HTTPie to test the root endpoint.
http :8080
You should see the following:
HTTP/1.1 200
...
Hello anonymous
This shows that you successfully made a request to the root endpoint of the unprotected Spring Boot resource server.
Create a Dinosaur Domain Model
What this world needs right now is some gigantic, prehistoric monsters, so, in order to demonstrate how to use Spring Data JPA, you’re going to create a dinosaur domain model and a dinosaur repository.
The first step in creating prehistoric monsters is, of course, adding the requisite dependencies to your Maven pom.xml file. You’re adding four dependencies.
spring-boot-starter-data-jpais the basic Spring Data JPA project meta-dependencyspring-boot-starter-data-restadds the REST interface capabilities to theCrudRepositoryh2tells Spring Data that you want to use an H2 database, which will default to the in-memory databaselombokis a helper that will allow us to easily generate some getters, setters, and a constructor in your data model class
pom.xml
<dependencies>
...
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-rest</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<provided>true</provided>
</dependency>
</dependencies>
Now create the dinosaur data model class itself. Notice the three annotations: @Getter @Setter @NoArgsConstructor. This is where Lombok is helping you to generate some boilerplate code. If you’re doing this tutorial in an IDE, you may need to enable annotation processing so Lombok can generate code for you. See Lombok’s instructions { Eclipse, IDEA } for more information.
src/main/java/com/example/sample/Dinosaur.java
package com.example.sample;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
@Getter @Setter @NoArgsConstructor
public class Dinosaur {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Long id;
private String name;
private boolean fangs;
private int numberOfArms;
private double weightTons;
@Override
public String toString() {
return String.format(
"Customer[id=%d, name='%s', fangs='%b', numberOfArms='%d', weightTons='%f']",
id, name, fangs, numberOfArms, weightTons);
}
}
This defines a dinosaur with five properties:
id: the unique identifier in the databasename: all things need names, even giant prehistoric monstersgenusAndSpecies: what is the scientific genus and species?fangs: cut to the chase, does the dinosaur have fangs?numberOfArms: how many grasping arms does it have?weightTons: how overwhelmingly enormous is it?
Now, these dinosaurs aren’t wreaking much havoc in your head. You need a way to create, read, update, and delete these dinosaurs. And don’t forget the DELETE part, that’s the mistake the movie made! If they had used Spring, they would have gotten DELETE automatically for free and, while it might not have been much of a movie, they would have survived.
Create a Spring Data Repository
Create a DinosaurRepository. This is the interface that will leverage Spring Data JPA to read and write the Dinosaur instances to and from the in-memory database.
Further, because you’re extending Spring’s CrudRepository repository, you will get a fully functioning REST interface automatically. If you don’t want or need the REST interface, or you want to create your own, you could subclass Repository.
There are two other relevant repository types: JpaRepository and PagingAndSortingRepository. All of these are part of a class hierarchy, building on Repository.
Repositoryis the base class. It adds the basic database functions.CrudRepositoryextendsRepositoryand adds the REST interface.PagingAndSortingRepositoryextendsCrudRepositoryand adds paging and sorting abilities.JpaRepositoryextendsPagingAndSortingRepositoryand adds a few JPA-related features, such as deleting batches of records and persistence context flushing.
Now create the DinosaurRepository.
src/main/java/com/example/sample/DinosaurRepository.java
package com.example.sample;
import org.springframework.data.repository.CrudRepository;
public interface DinosaurRepository extends CrudRepository<Dinosaur, Long> {
}
You’ll notice there’s not much there. If you look at the CrudRepository superclass, you’ll see the methods that are being implemented and exposed by the repository.
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S var1);
<S extends T> Iterable<S> saveAll(Iterable<S> var1);
Optional<T> findById(ID var1);
boolean existsById(ID var1);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> var1);
long count();
void deleteById(ID var1);
void delete(T var1);
void deleteAll(Iterable<? extends T> var1);
void deleteAll();
}
Now you can test the automatically generated REST resource. Use Control-C to stop the running process if you haven’t already and run it again.
./mvnw spring-boot:run
Then, hit the /dinosaurs endpoint to see the response.
http :8080/dinosaurs
Since you don’t have any dinosaurs, the results aren’t very exciting. All you have is an empty array along with some HATEOAS (Hypertext As The Engine Of Application State) and HAL (Hypertext Application Language) links.
HTTP/1.1 200
...
{
"_embedded": {
"dinosaurs": []
},
"_links": {
"profile": {
"href": "http://localhost:8080/profile/dinosaurs"
},
"self": {
"href": "http://localhost:8080/dinosaurs"
}
}
}
Spring Data REST uses HATEOAS and HAL to return formatted data. Very, very briefly: HAL is a descriptive resource language that uses published links to point to resources. It allows a resource server to describe itself to its clients. You can read more about it on the Spring Data REST page.
If you want to avoid exposing the REST resource entirely, you can annotate the DinosaurRepository in the following way. This disables the REST resource.
@RepositoryRestResource(exported=false)
public interface DinosaurRepository extends CrudRepository<Dinosaur, Long> {
}
Further, if you wanted to hide only certain CRUD methods, you can use the @RestResource(exported = false) annotation on individual methods. Let’s say you want to disable the delete methods for the dinosaurs (cue maniacal laughing and hand wringing).
Go ahead and update your DinosaurRepository to match the following:
src/main/java/com/example/sample/DinosaurRepository.java
package com.example.sample;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.repository.CrudRepository;
import org.springframework.data.rest.core.annotation.RestResource;
import org.springframework.data.rest.core.config.RepositoryRestConfiguration;
import org.springframework.data.rest.webmvc.config.RepositoryRestConfigurer;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
public interface DinosaurRepository extends CrudRepository<Dinosaur, Long> {
@Override
@RestResource(exported = false)
void deleteById(Long id);
@Override
@RestResource(exported = false)
void delete(Dinosaur entity);
@Configuration
static class RepositoryConfig implements RepositoryRestConfigurer {
@Override
public void configureRepositoryRestConfiguration(RepositoryRestConfiguration config, CorsRegistry corsRegistry) {
config.exposeIdsFor(Dinosaur.class);
}
}
}
The general idea is to override the particular subclass method to be hidden and mark them so they’re not exported. Notice that in this case, to hide the delete methods, you have to hide both of the subclass’s delete methods.
I also slipped another change into the file. I added the RepositoryConfig static class to configure Spring to return the entity IDs with the JSON. Spring doesn’t do that by default, and it’s handy to do that in this example to demonstrate the CRUD methods.
Before you try this all out, create some bootstrapped demo data to be loaded into the database. Create a src/main/resources/data.sql file that will be run upon application initialization only when the H2 in-memory database is being used.
src/main/resources/data.sql
INSERT INTO dinosaur (name, fangs, number_of_arms, weight_tons) VALUES
('Terror Bird', true, 2, 100),
('Ankylosaurus', true, 4, 350.5),
('Spinosaurus', false, 4, 500);
Remember these are recombinant, mutated dinosaurs, not actual dinosaurs, so they have extra arms.
Then, add the following property to src/main/resources/application.properties:
spring.jpa.defer-datasource-initialization=true
Thanks to Pranay Singhal for the tip! You can read more about why this is necessary on Stack Overflow.
Test Your Spring Data JPA-Powered REST API
Now, try it out. Run the Spring Boot app (Control-C if necessary).
./mvnw spring-boot:run
Perform a GET request on the /dinosaur REST endpoint.
http :8080/dinosaurs
You’ll see the following (with some elements omitted for clarity):
HTTP/1.1 200
...
{
"_embedded": {
"dinosaurs": [
{
...
"fangs": true,
"id": 1
"name": "Terror Bird",
"numberOfArms": 2,
"weightTons": 100.0
},
{
...
"fangs": true,
"id": 2
"name": "Ankylosaurus",
"numberOfArms": 4,
"weightTons": 350.5
},
{
...
"fangs": false,
"id": 3
"name": "Spinosaurus",
"numberOfArms": 4,
"weightTons": 500.0
}
]
},
...
}
Try to delete one of the dinosaurs.
http DELETE :8080/dinosaurs/1
The response should be a 405 error. HTTP 405 is “method not allowed.” Evil laughter. And, the dinosaurs take over the world.
To avert disaster, remove the two @Override methods from the DinosaurRepository.
src/main/java/com/example/sample/DinosaurRepository.java
package com.example.sample;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.repository.CrudRepository;
import org.springframework.data.rest.core.config.RepositoryRestConfiguration;
import org.springframework.data.rest.webmvc.config.RepositoryRestConfigurer;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
public interface DinosaurRepository extends CrudRepository<Dinosaur, Long> {
@Configuration
static class RepositoryConfig implements RepositoryRestConfigurer {
@Override
public void configureRepositoryRestConfiguration(RepositoryRestConfiguration config, CorsRegistry corsRegistry) {
config.exposeIdsFor(Dinosaur.class);
}
}
}
Stop (Control-C) and re-start the Spring Boot app.
./mvnw spring-boot:run
Delete it again using HTTPie.
http DELETE :8080/dinosaurs/1
...
HTTP/1.1 204
...
HTTP 204 implies “no content.” The server has successfully performed the delete and has nothing else to say about it. If you perform a GET request (http :8080/dinosaurs), you’ll see one less dinosaur. Crisis averted!
The only thing left to do is to secure the whole thing so random foreign net-bots aren’t creating dinosaurs willy-nilly.
Implement an OAuth 2.0 Resource Server
Thanks to Okta’s Spring Boot Starter, most of the OAuth is already in place. All you need to do to activate it is update your SecurityConfiguration class. The following code configures the application to authorize all requests using JWTs and OAuth 2.0.
package com.example.sample;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
@EnableWebSecurity
public class SecurityConfiguration extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests(authorizeRequests -> authorizeRequests.anyRequest().authenticated())
.oauth2ResourceServer().jwt();
}
}
Remember that you or the Okta CLI put the necessary OAuth configuration for Okta in the src/main/resources/application.properties file, which should look something like the following:
okta.oauth2.issuer=${env.ISSUER}
okta.oauth2.client-id=${env.CLIENT_ID}
okta.oauth2.client-secret=${env.CLIENT_SECRET}
The env.* variables are read from .okta.env using spring-dotenv.
Stop (Control-C) and re-start the Spring Boot app.
./mvnw spring-boot:run
Run a GET on the dinosaur service.
http :8080/dinosaurs
It’s now locked down.
HTTP/1.1 401
...
Generate an Access Token JWT
You used Okta as your OAuth 2.0 and OpenID Connect (OIDC) provider when you used the Okta CLI. The CLI created an OIDC application for you on the Okta developer site and populated the config details in a .okta.env file. Your application is now expecting a JSON Web Token (JWT) when you make requests.
IMPORTANT: Keep your secrets out of source control by adding okta.env to your .gitignore file:
echo .okta.env >> .gitignore
To generate a JWT, you can use the OIDC Debugger.
However, before you do that, you need to add a login redirect URI to your OIDC application. Navigate to the developer dashboard at https://developer.okta.com. If this is your first time logging in, you may need to click the Admin button.
Click on Applications in the top menu.
In the panel, select the okta-spring-boot-sample application (the one that the CLI generated for you).
Select the General tab. Click Edit.
Add a new entry under Login redirect URIs: https://oidcdebugger.com/debug
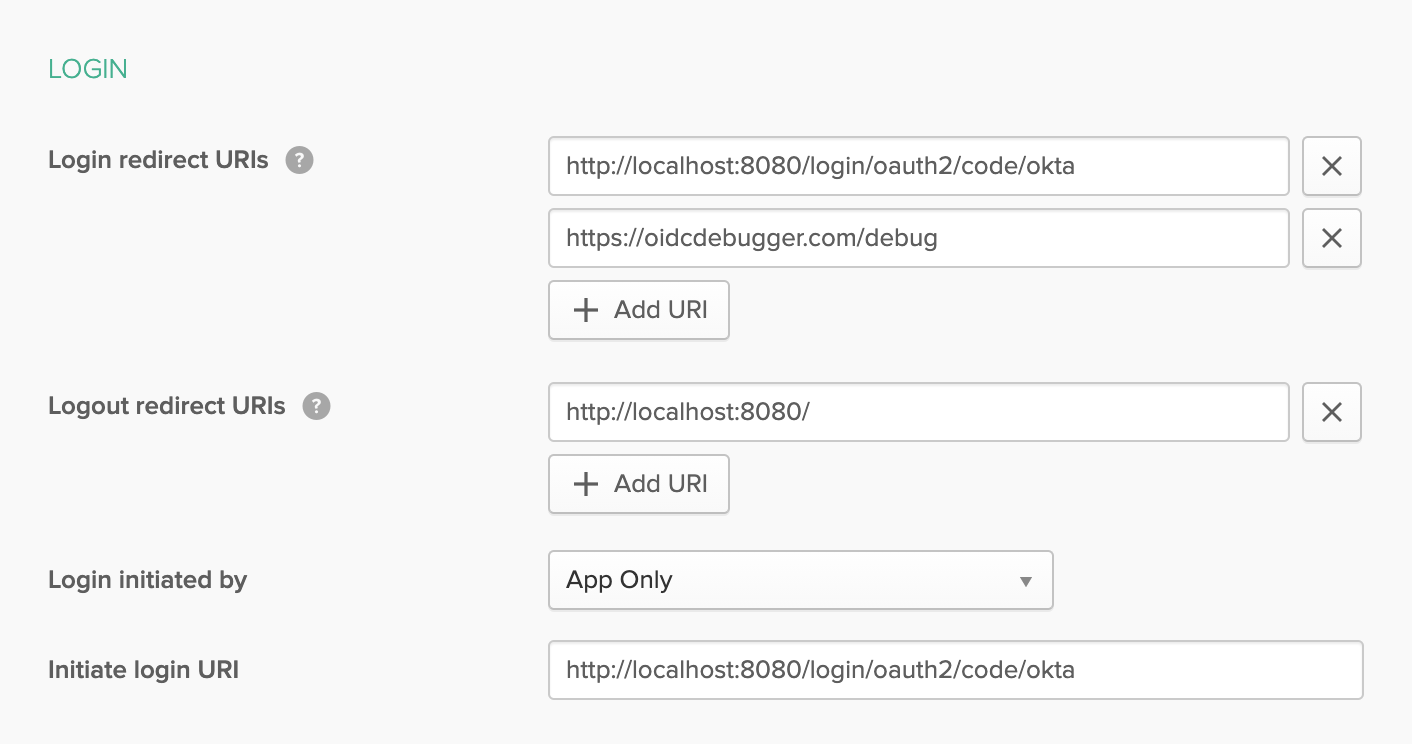
Click Save.
Take note of the OIDC applications Client ID and Client Secret at the bottom. You’ll need both of those values in just a moment.
Open the OIDC Debugger at https://oidcdebugger.com.
Fill in the following values:
- Authorization URI:
https://{yourOktaDomain}/oauth2/default/v1/authorize(update {yourOktaDomain} with your actual Okta domain, something likedev-1234567.okta.com - Redirect URI:
https://oidcdebugger.com/debug(default value) - Client ID: the client ID from your OIDC application above
- Scope:
openid(default value) - State: any value (in production this is used to protect against cross-site request forgery)
- Response type:
code
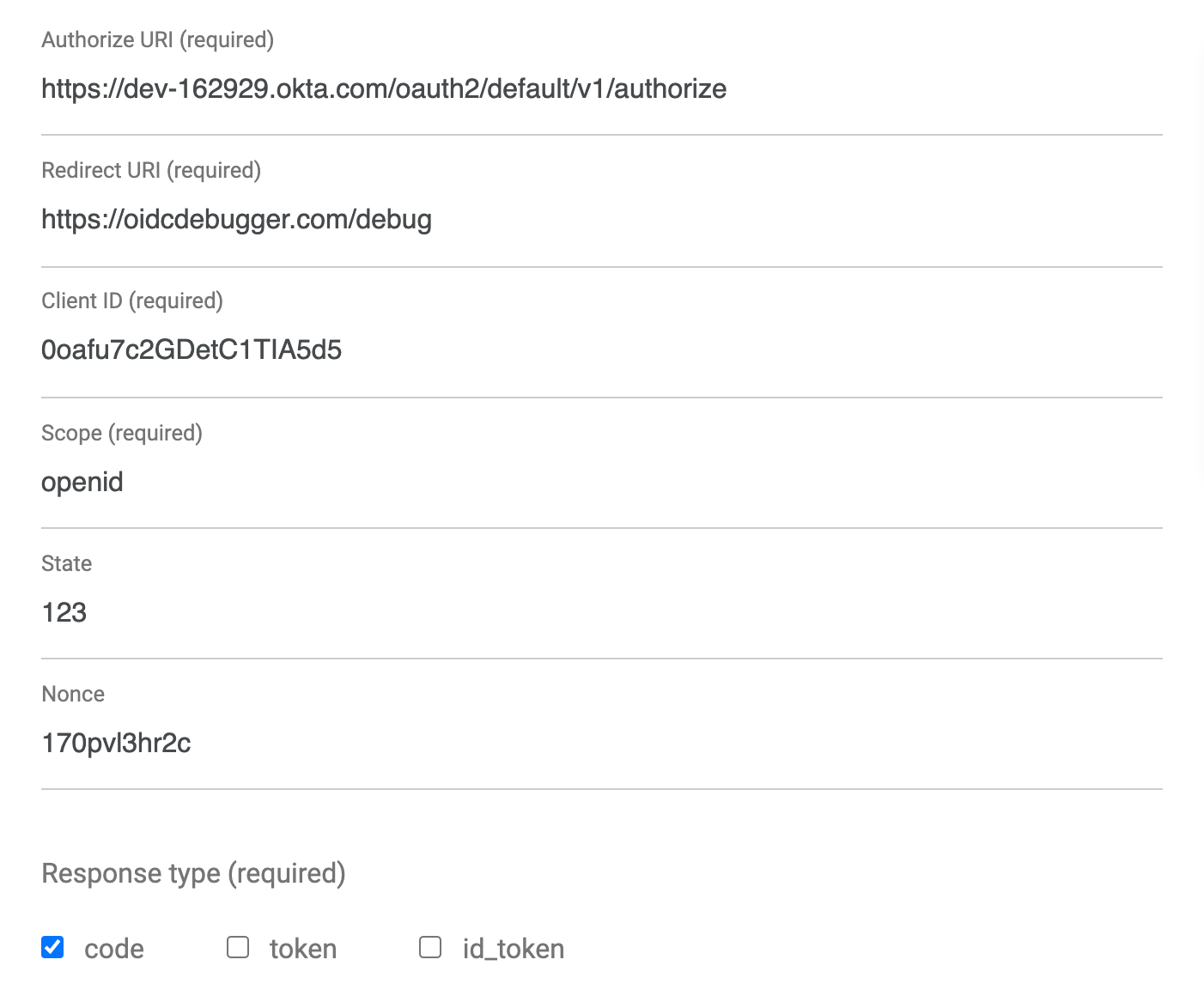
Click SEND REQUEST at the bottom of the form.
You should see an authorization code.

You need to exchange this code for a token. You can use HTTPie. Don’t forget to fill in the values in brackets: the authorization code, your Okta domain, your OIDC app client ID, and your OIDC app client secret.
http -f https://{yourOktaDomain}/oauth2/default/v1/token \
grant_type=authorization_code \
code={yourAuthCode} \
client_id={clientId} \
client_secret={clientSecret} \
redirect_uri=https://oidcdebugger.com/debug
You should get a JSON response that includes an access token and an ID token.
HTTP/1.1 200 OK
Cache-Control: no-cache, no-store
Connection: keep-alive
...
{
"access_token": "eyJraWQiOiJycGZWTzd4R2hDWmlvUXdrWWha...",
"expires_in": 3600,
"id_token": "eyJraWQiOiJycGZWTzd4R2hDWmlvUXdrWWhaSkph...",
"scope": "openid",
"token_type": "Bearer"
}
Access Your API with an OAuth 2.0 Bearer Token
Copy the resulting access_token value to the clipboard, and in the terminal where you are running your HTTPie commands, save the token value to a shell variable, like this:
TOKEN=eyJraWQiOiJxMm5rZmtwUDRhMlJLV2REU2JfQ...
Now you can use the token in a request.
http :8080/dinosaurs "Authorization: Bearer $TOKEN"
You should see your list of dinosaurs. 🦖
Learn More About Spring Data and Spring Boot
In this tutorial, you took a look at Spring Data in general and saw how it is an umbrella project. It encompasses a huge range of technologies that are designed to make persisting and manipulating data easy across widely divergent technologies without sacrificing technical flexibility.
As an example of this, you used Spring Data JPA to create a simple relational database model and repository. You used Spring’s CrudRepository class and saw how it automatically created a resource server from your data model. Finally, you used Okta’s OAuth 2.0 and OIDC implementation to quickly and easily add JWT authentication to your resource server. All of this was bootstrapped by Okta’s CLI.
You can find the source code for this example on GitHub, in the oktadev/okta-spring-data-jpa-example.
If you liked this post, you might like similar ones on Spring Data and Spring Boot:
- Test in Production with Spring Security and Feature Flags
- Build a Basic App with Spring Boot and JPA using PostgreSQL
- Data Persistence with Hibernate and Spring
- Use Spring Boot and MySQL to go Beyond Authentication
If you have any questions about this post, please add a comment below. For more awesome content, follow @oktadev on Twitter, like us on Facebook, or subscribe to our YouTube channel. We also stream on Twitch every week.
Changelog:
- Jan 25, 2022:
Updated to use
.okta.envinstead ofapplication.properties. This change is necessary since the okta-spring-boot-sample now uses dotenv to load Okta settings. Changes to this post can be viewed in okta-blog#1050. - Jun 23, 2021:
Add
spring.jpa.defer-datasource-initialization=truetoapplication.propertiesfor Spring Boot 2.5. Thanks to Pranay Singhal for the tip! You can see changes in this post at okta-blog#820. Changes in the example can be viewed in okta-spring-data-jpa-example#5. - Jan 26, 2021: Updated post to use Spring Boot 2.4.2 and Spring Data 2020.0. See the code changes in the example on GitHub. Changes to this post can be viewed in okta-blog#536
Okta Developer Blog Comment Policy
We welcome relevant and respectful comments. Off-topic comments may be removed.