How to Prevent Reactive Java Applications from Stalling

Modern applications must work smoothly on high loads and with a high number of concurrent users. Traditional Java applications run blocking code and a common approach for scaling is to increase the number of available threads. When latency comes into the picture, many of these additional threads sit idle, wasting resources.
A different approach increases efficiency by writing asynchronous non-blocking code that lets the execution switch to another task while the asynchronous process completes.
Project Reactor is a Java framework from VMware that implements the Reactive Streams specification. This initiative provides a standard for asynchronous stream processing with non-blocking backpressure for the JVM and JavaScript runtimes. It is the foundation of the reactive stack in the Spring ecosystem and WebFlux applications. Some studies suggest that performance differences are negligible in Spring applications unless the application makes more than 500 API requests per second. Thus, it’s not mandatory to do asynchronous programming, but it is the right approach for specific use cases.
In this post, we’ll summarize some core Reactor concepts, introduce the Scheduler abstraction, and describe how it is used to encapsulate blocking code and prevent Java reactive applications from stalling.
Prerequisites:
Table of Contents
Note: In May 2025, the Okta Integrator Free Plan replaced Okta Developer Edition Accounts, and the Okta CLI was deprecated.
We preserved this post for reference, but the instructions no longer work exactly as written. Replace the Okta CLI commands by manually configuring Okta following the instructions in our Developer Documentation.
Reactor Execution Model
Reactor is an API for doing asynchronous programming. You describe your data processing as a flow of operators, composing a data-processing pipeline.

Using the assembly line analogy, the initial data flow from a source, known as the Publisher, goes through transformation steps and eventually the result is pushed to a consumer, known as the Subscriber. A Publisher produces data, and a Subscriber listens to it. Reactor also supports flow control via backpressure, so a Subscriber can signal the volume it’s able to consume.
Nothing Happens Until You Subscribe
In general, when you instantiate a Publisher (a Flux or a Mono) you are describing an asynchronous processing pipeline. When combining operators, no processing happens–you are describing the intent. This is called assembly time. You only trigger the data flow through that pipeline when you subscribe. The subscribe call emits a signal back to the source, and the source starts emitting data that flows through the pipeline. This is called execution time or subscription time.
A cold publisher generates data for each subscription. Then, if you subscribe twice, it will generate the data twice. All the examples that follow below will instantiate cold publishers. On the other hand, a hot publisher starts emitting data immediately or on the first subscription. Late subscribers receive data emitted after they subscribe. For the family of hot publishers, something does indeed happen before you subscribe.
Operators map and flatMap
Operators are like workstations in an assembly line. They make it possible to describe transformations or intermediate steps along the processing chain. Each operator is a decorator, it wraps the previous Publisher into a new instance. To avoid mistakes, the preferred way of using operators is to chain the calls. Apply the next operator to the last operator’s result. Some operators are instance methods and others are static methods.
Both map() and flatMap() are instance method operators. You might be familiar with the concept of these operations from functional programming or Java Streams. In the reactive world, they have their own semantics.
The map() method transforms the emitted items by applying a synchronous function to each item, on a one-to-one basis. Check the example below:
public class MapTest {
private static Logger logger = LoggerFactory.getLogger(MapTest.class);
@Test
public void mapTest() {
Flux.range(1, 5)
.map(v -> transform(v))
.subscribe(y -> logger.info(y));
}
private String transform(Integer i){
return String.format("%03d", i);
}
}
Note: You can find this test and all the code in this tutorial in GitHub.
In the code above, a flux is created from a range of integers from 1 to 5. The map() operator is passed a transformation function that formats with leading zeros. Notice that the return type of the transform method is not a publisher and the transformation is synchronous–a simple method call. The transformation function must not introduce latency.
The flatMap() method transforms the emitted items asynchronously into Publishers, then flattens these inner publishers into a single Flux through merging, and the items can interleave. This operator does not necessarily preserve original ordering. The mapper function passed to flatMap() transforms the input sequence into N sequences. This operator is suitable for running an asynchronous task for each item.
In the example below, a list of words is mapped to its phonetics through the Dictionary API, using flatMap().
@SpringBootTest
@ActiveProfiles("test")
public class FlatMapTest {
private static Logger logger = LoggerFactory.getLogger(FlatMapTest.class);
public static class Word {
private String word;
private List<Phonetic> phonetics;
private List<Meaning> meanings;
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public List<Phonetic> getPhonetics() {
return phonetics;
}
public void setPhonetics(List<Phonetic> phonetics) {
this.phonetics = phonetics;
}
public List<Meaning> getMeanings() {
return meanings;
}
public void setMeanings(List<Meaning> meanings) {
this.meanings = meanings;
}
}
public static class Meaning {
private String partOfSpeech;
private List<Definition> definitions;
public String getPartOfSpeech() {
return partOfSpeech;
}
public void setPartOfSpeech(String partOfSpeech) {
this.partOfSpeech = partOfSpeech;
}
public List<Definition> getDefinitions() {
return definitions;
}
public void setDefinitions(List<Definition> definitions) {
this.definitions = definitions;
}
}
public static class Definition {
private String definition;
private String example;
public String getDefinition() {
return definition;
}
public void setDefinition(String definition) {
this.definition = definition;
}
public String getExample() {
return example;
}
public void setExample(String example) {
this.example = example;
}
}
public static class Phonetic {
private String text;
private String audio;
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public String getAudio() {
return audio;
}
public void setAudio(String audio) {
this.audio = audio;
}
}
@Configuration
public static class FlatMapTestConfig {
@Bean
public WebClient webClient(){
WebClient webClient = WebClient.builder()
.baseUrl("https://api.dictionaryapi.dev/api/v2/entries/en_US")
.build();
return webClient;
}
}
@Autowired
private WebClient webClient;
@Test
public void flatMapTest() throws InterruptedException {
List<String> words = new ArrayList<>();
words.add("car");
words.add("key");
words.add("ballon");
Flux.fromStream(words.stream())
.flatMap(w -> getPhonetic(w))
.subscribeOn(Schedulers.boundedElastic())
.subscribe(y -> logger.info(y));
Thread.sleep(5000);
}
private Mono<String> getPhonetic(String word){
Mono<String> response = webClient.get()
.uri("/" + word).retrieve().bodyToMono(Word[].class)
.map(r -> r[0].getPhonetics().get(0).getText());
return response;
}
}
There is a rich vocabulary of operators for Flux and Mono you can find in the reference documentation. This handy guide can help you choose the right operator: “Which operator do I need?”.
Reactor Schedulers for Switching the Thread
Project Reactor provides the tools for fine-tuning the asynchronous processing in terms of threads and execution context.
The Scheduler is an abstraction on top of the ExecutionService, which allows submitting a task immediately, after a delay or at a fixed time rate. We’ll share some examples below of the various default schedulers provided. The execution context is defined by the Scheduler selection.
Schedulers are selected through subscribeOn() and publishOn() operators, they switch the execution context. subscribeOn() changes the thread where the source actually starts generating data. It changes the root of the chain, affecting the preceding operators, upstream in the chain; and also affects subsequent operators.
Using publishOn() switches the context for the following operators in the pipeline description, downstream in the chain, overriding any the scheduler assigned with subscribeOn().
The scheduler examples ahead will use TestUtils.debug for logging the thread name, function, and element:
public class TestUtils {
public static Logger logger = LoggerFactory.getLogger(TestUtils.class);
public static <T> T debug(T el, String function) {
logger.info("element "+ el + " [" + function + "]");
return el;
}
}
No Execution Context
Schedulers.immediate() can be seen as the no-op scheduler, which the pipeline executes in the current thread.
@Test
public void immediateTest() {
logger.info("Schedulers.immediate()");
Flux.range(1, 5)
.map(v -> debug(v, "map"))
.subscribeOn(Schedulers.immediate())
.subscribe(w -> debug(w,"subscribe"));
}
The test above will log something similar to:
2021-07-29 09:36:05.905 - INFO [main] - element "1" [map]
2021-07-29 09:36:05.906 - INFO [main] - element "1" [subscribe]
2021-07-29 09:36:05.906 - INFO [main] - element "2" [map]
2021-07-29 09:36:05.906 - INFO [main] - element "2" [subscribe]
2021-07-29 09:36:05.906 - INFO [main] - element "3" [map]
2021-07-29 09:36:05.907 - INFO [main] - element "3" [subscribe]
2021-07-29 09:36:05.907 - INFO [main] - element "4" [map]
2021-07-29 09:36:05.907 - INFO [main] - element "4" [subscribe]
2021-07-29 09:36:05.907 - INFO [main] - element "5" [map]
2021-07-29 09:36:05.907 - INFO [main] - element "5" [subscribe]
Everything executes in the main thread.
Single Reusable Thread
@Test
public void singleTest() throws InterruptedException {
logger.info("Schedulers.single()");
Flux.range(1, 5)
.map(v -> debug(v, "map"))
.publishOn(Schedulers.single())
.subscribe(w -> debug(w,"subscribe"));
Thread.sleep(5000);
}
When running the test above, you will see a log similar to this:
2021-07-13 23:19:16.456 - INFO [main] - element 1 [map]
2021-07-13 23:19:16.457 - INFO [main] - element 2 [map]
2021-07-13 23:19:16.457 - INFO [main] - element 3 [map]
2021-07-13 23:19:16.457 - INFO [main] - element 4 [map]
2021-07-13 23:19:16.457 - INFO [main] - element 5 [map]
2021-07-13 23:19:16.457 - INFO [single-1] - element 1 [subscribe]
2021-07-13 23:19:16.465 - INFO [single-1] - element 2 [subscribe]
2021-07-13 23:19:16.465 - INFO [single-1] - element 3 [subscribe]
2021-07-13 23:19:16.466 - INFO [single-1] - element 4 [subscribe]
2021-07-13 23:19:16.466 - INFO [single-1] - element 5 [subscribe]
As you can see, the map() function executes in the main thread, and the consumer code passed to subscribe() executes in the single-1 thread. Everything after the publishOn() will execute in the passed scheduler.
You may have noticed there is a Thread.sleep() call at the end of the test. As part of the work is passed to another thread, the sleep() call delays the application exit, so the worker thread can complete the task.
Bounded Elastic Thread Pool
A bounded elastic thread pool is a better choice for I/O blocking work, for example, reading a file, or making a blocking network call. It serves to help with legacy blocking code if it cannot be avoided.
@Test
public void boundedElasticTest() throws InterruptedException {
logger.info("Schedulers.boundedElastic()");
List<String> words = new ArrayList<>();
words.add("a.txt");
words.add("b.txt");
words.add("c.txt");
Flux flux = Flux.fromArray(words.toArray(new String[0]))
.publishOn(Schedulers.boundedElastic())
.map(w -> scanFile(debug(w, "map")));
flux.subscribe(y -> debug(y, "subscribe1"));
flux.subscribe(y -> debug(y, "subscribe2"));
Thread.sleep(5000);
}
public String scanFile(String filename){
InputStream stream = getClass().getClassLoader().getResourceAsStream(filename);
Scanner scanner = new Scanner(stream);
String line = scanner.nextLine();
scanner.close();
return line;
}
The test above should log something similar to this:
2021-07-15 00:41:51.443 - INFO [boundedElastic-1] - element "a.txt" [map]
2021-07-15 00:41:51.443 - INFO [boundedElastic-2] - element "a.txt" [map]
2021-07-15 00:41:51.446 - INFO [boundedElastic-2] - element "A line in file a.txt" [subscribe2]
2021-07-15 00:41:51.447 - INFO [boundedElastic-2] - element "b.txt" [map]
2021-07-15 00:41:51.447 - INFO [boundedElastic-2] - element "A line in file b.txt" [subscribe2]
2021-07-15 00:41:51.447 - INFO [boundedElastic-2] - element "c.txt" [map]
2021-07-15 00:41:51.448 - INFO [boundedElastic-2] - element "A line in file c.txt" [subscribe2]
2021-07-15 00:41:51.448 - INFO [boundedElastic-1] - element "A line in file a.txt" [subscribe1]
2021-07-15 00:41:51.449 - INFO [boundedElastic-1] - element "b.txt" [map]
2021-07-15 00:41:51.451 - INFO [boundedElastic-1] - element "A line in file b.txt" [subscribe1]
2021-07-15 00:41:51.452 - INFO [boundedElastic-1] - element "c.txt" [map]
2021-07-15 00:41:51.453 - INFO [boundedElastic-1] - element "A line in file c.txt" [subscribe1]
As you can see in the code above, the flux() is subscribed twice. As the publishOn() is invoked before any operator, everything will execute in the context of a bounded elastic thread. Also, notice how the execution from both subscriptions can interleave.
What might be confusing is that each subscription is assigned one bounded elastic thread for the whole execution. So in this case, “subscription1” executed in boundedElastic-1 and “subscription2” executed in boundedElastic-2. All operations for a given subscription execute in the same thread.
The instantiation of the Flux above produced a Cold Publisher, a publisher that generates data anew for each subscription. That’s why both subscriptions above process all the values.
Fixed Pool of Workers
Schedulers.parallel() provides a pool of workers tuned for parallel work, with as many workers as there are CPU cores.
@Test
public void parallelTest() throws InterruptedException {
logger.info("Schedulers.parallel()");
Flux flux = Flux.range(1, 5)
.publishOn(Schedulers.parallel())
.map(v -> debug(v, "map"));
flux.subscribe(w -> debug(w,"subscribe1"));
flux.subscribe(w -> debug(w,"subscribe2"));
flux.subscribe(w -> debug(w,"subscribe3"));
flux.subscribe(w -> debug(w,"subscribe4"));
flux.subscribe(w -> debug(w,"subscribe5"));
Thread.sleep(5000);
}
The test above will log something similar to the following lines:
2021-07-15 22:57:33.435 - INFO [parallel-2] - element "1" [map]
2021-07-15 22:57:33.435 - INFO [parallel-2] - element "1" [subscribe2]
2021-07-15 22:57:33.435 - INFO [parallel-1] - element "1" [map]
2021-07-15 22:57:33.435 - INFO [parallel-2] - element "2" [map]
2021-07-15 22:57:33.435 - INFO [parallel-2] - element "2" [subscribe2]
2021-07-15 22:57:33.435 - INFO [parallel-1] - element "1" [subscribe1]
2021-07-15 22:57:33.435 - INFO [parallel-1] - element "2" [map]
2021-07-15 22:57:33.436 - INFO [parallel-1] - element "2" [subscribe1]
2021-07-15 22:57:33.436 - INFO [parallel-2] - element "3" [map]
2021-07-15 22:57:33.436 - INFO [parallel-1] - element "3" [map]
2021-07-15 22:57:33.436 - INFO [parallel-2] - element "3" [subscribe2]
2021-07-15 22:57:33.436 - INFO [parallel-1] - element "3" [subscribe1]
2021-07-15 22:57:33.436 - INFO [parallel-1] - element "4" [map]
2021-07-15 22:57:33.436 - INFO [parallel-2] - element "4" [map]
2021-07-15 22:57:33.436 - INFO [parallel-1] - element "4" [subscribe1]
2021-07-15 22:57:33.436 - INFO [parallel-2] - element "4" [subscribe2]
2021-07-15 22:57:33.436 - INFO [parallel-1] - element "5" [map]
2021-07-15 22:57:33.436 - INFO [parallel-2] - element "5" [map]
2021-07-15 22:57:33.436 - INFO [parallel-1] - element "5" [subscribe1]
2021-07-15 22:57:33.436 - INFO [parallel-2] - element "5" [subscribe2]
2021-07-15 22:57:33.438 - INFO [parallel-3] - element "1" [map]
2021-07-15 22:57:33.438 - INFO [parallel-3] - element "1" [subscribe3]
2021-07-15 22:57:33.439 - INFO [parallel-3] - element "2" [map]
2021-07-15 22:57:33.439 - INFO [parallel-3] - element "2" [subscribe3]
2021-07-15 22:57:33.439 - INFO [parallel-3] - element "3" [map]
2021-07-15 22:57:33.439 - INFO [parallel-3] - element "3" [subscribe3]
2021-07-15 22:57:33.441 - INFO [parallel-4] - element "1" [map]
2021-07-15 22:57:33.441 - INFO [parallel-3] - element "4" [map]
2021-07-15 22:57:33.442 - INFO [parallel-4] - element "1" [subscribe4]
2021-07-15 22:57:33.445 - INFO [parallel-1] - element "1" [map]
2021-07-15 22:57:33.445 - INFO [parallel-4] - element "2" [map]
2021-07-15 22:57:33.445 - INFO [parallel-4] - element "2" [subscribe4]
2021-07-15 22:57:33.445 - INFO [parallel-1] - element "1" [subscribe5]
2021-07-15 22:57:33.445 - INFO [parallel-4] - element "3" [map]
2021-07-15 22:57:33.445 - INFO [parallel-4] - element "3" [subscribe4]
2021-07-15 22:57:33.445 - INFO [parallel-1] - element "2" [map]
2021-07-15 22:57:33.445 - INFO [parallel-4] - element "4" [map]
2021-07-15 22:57:33.445 - INFO [parallel-1] - element "2" [subscribe5]
2021-07-15 22:57:33.445 - INFO [parallel-4] - element "4" [subscribe4]
2021-07-15 22:57:33.445 - INFO [parallel-1] - element "3" [map]
2021-07-15 22:57:33.445 - INFO [parallel-4] - element "5" [map]
2021-07-15 22:57:33.445 - INFO [parallel-4] - element "5" [subscribe4]
2021-07-15 22:57:33.445 - INFO [parallel-1] - element "3" [subscribe5]
2021-07-15 22:57:33.442 - INFO [parallel-3] - element "4" [subscribe3]
2021-07-15 22:57:33.450 - INFO [parallel-3] - element "5" [map]
2021-07-15 22:57:33.450 - INFO [parallel-3] - element "5" [subscribe3]
2021-07-15 22:57:33.450 - INFO [parallel-1] - element "4" [map]
2021-07-15 22:57:33.450 - INFO [parallel-1] - element "4" [subscribe5]
2021-07-15 22:57:33.450 - INFO [parallel-1] - element "5" [map]
2021-07-15 22:57:33.450 - INFO [parallel-1] - element "5" [subscribe5]
As you can see, different subscription executions interleave, and as I am testing with only four CPU cores, four workers seem to be available: parallel-1, parallel-2, parallel-3, and parallel-4. The subscription5 operations, execute in parallel-1.
Again, observe how all operations for a given subscription are executed in the same thread.
Using Both publishOn and subscribeOn
When the publishOn() and subscribeOn() operators are used, the subscribe call accepts a consumer. The consumer will execute in the context selected by publishOn(), which defines the scheduler for downstream processing, including the consumer execution. At first, this might be confusing to understand, so check the following example:
@Test
public void subscribeOnWithPublishOnTest() throws InterruptedException {
Flux.range(1, 3)
.map(v -> debug(v, "map1"))
.publishOn(Schedulers.parallel())
.map(v -> debug(v * 100, "map2"))
.subscribeOn(Schedulers.boundedElastic())
.subscribe(w -> debug(w,"subscribe"));
Thread.sleep(5000);
}
The log should look like the following lines:
2021-07-29 08:40:30.583 - INFO [boundedElastic-1] - element "1" [map1]
2021-07-29 08:40:30.584 - INFO [parallel-1] - element "100" [map2]
2021-07-29 08:40:30.585 - INFO [parallel-1] - element "100" [subscribe]
2021-07-29 08:40:30.585 - INFO [boundedElastic-1] - element "2" [map1]
2021-07-29 08:40:30.585 - INFO [parallel-1] - element "200" [map2]
2021-07-29 08:40:30.585 - INFO [parallel-1] - element "200" [subscribe]
...
As you can see, the first map() operator executes in the boundedElastic-1 thread, the second map() operator and the subscribe() consumer execute in the parallel-1 thread. Notice that the subscribeOn() operator is invoked after publishOn(), but it affects the root of the chain and the operators preceding publishOn() anyways.
A probably simplified marble diagam for the example above might look like this:
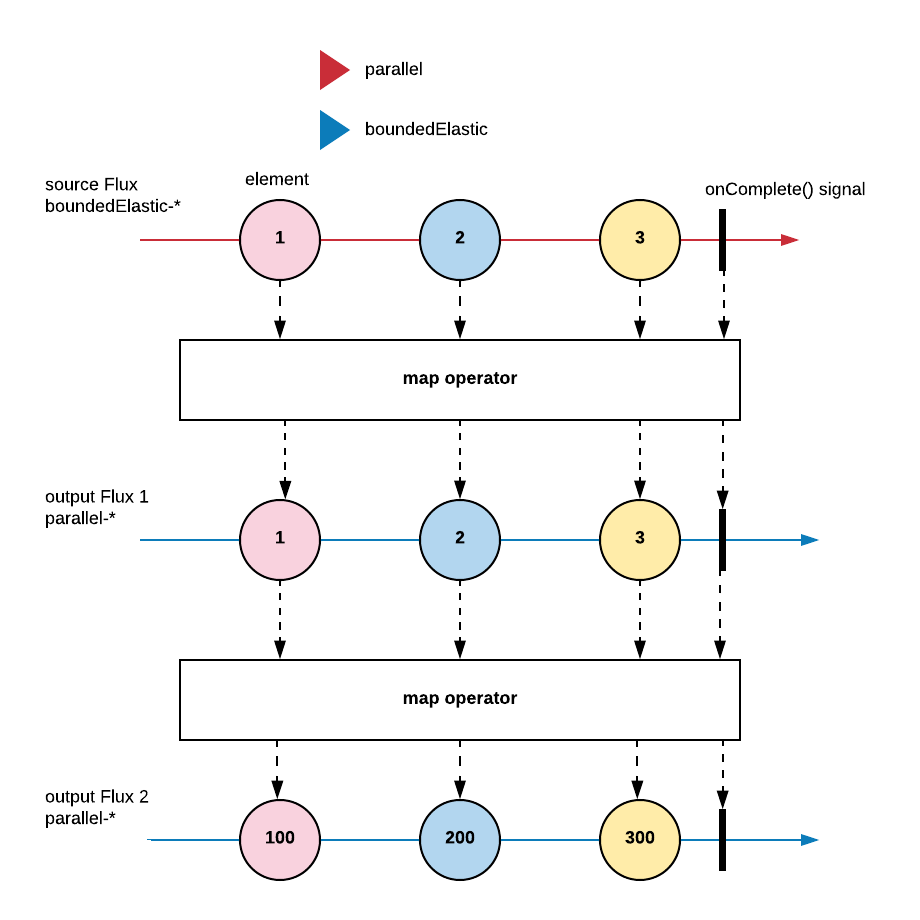
Reactive Java Spring Services
In Spring WebFlux, it is assumed applications don’t block, so non-blocking servers use a small fixed-size thread pool to handle requests, named event loop workers.
In an ideal reactive scenario, all the architecture components are non-blocking, so there is no need to worry about the event loop freezing up (reactor meltdown). But sometimes, you will have to deal with legacy blocking code, or blocking libraries.
So now, let’s experiment with Reactor Schedulers in a Reactive Java application. Create a Spring WebFlux service with Okta security. The service will expose an endpoint to return a random integer.
The implementation will call Java SecureRandom blocking code. Start by downloading a Spring Boot Maven project using Spring Initializr. You can do it with the following HTTPie command:
http -d https://start.spring.io/starter.zip \
bootVersion==2.5.3 \
baseDir==reactive-service \
groupId==com.okta.developer.reactive \
artifactId==reactive-service \
name==reactive-service \
packageName==com.okta.developer.reactive \
javaVersion==11 \
dependencies==webflux,okta
Unzip the project:
unzip reactive-service.zip
cd reactive-service
Before you begin, you’ll need a free Okta developer account. Install the Okta CLI and run okta register to sign up for a new account. If you already have an account, run okta login.
Then, run okta apps create. Select the default app name, or change it as you see fit.
Choose Web and press Enter.
Select Okta Spring Boot Starter.
Accept the default Redirect URI values provided for you. That is, a Login Redirect of http://localhost:8080/login/oauth2/code/okta and a Logout Redirect of http://localhost:8080.
What does the Okta CLI do?
The Okta CLI will create an OIDC Web App in your Okta Org. It will add the redirect URIs you specified and grant access to the Everyone group. You will see output like the following when it’s finished:
Okta application configuration has been written to:
/path/to/app/src/main/resources/application.properties
Open src/main/resources/application.properties to see the issuer and credentials for your app.
okta.oauth2.issuer=https://dev-133337.okta.com/oauth2/default
okta.oauth2.client-id=0oab8eb55Kb9jdMIr5d6
okta.oauth2.client-secret=NEVER-SHOW-SECRETS
NOTE: You can also use the Okta Admin Console to create your app. See Create a Spring Boot App for more information.
Create the package com.okta.developer.reactive.service, and add the SecureRandomService interface:
package com.okta.developer.reactive.service;
import reactor.core.publisher.Mono;
public interface SecureRandomService {
Mono<Integer> getRandomInt();
}
And the implementation SecureRandomServiceImpl:
package com.okta.developer.reactive.service;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Mono;
import java.security.SecureRandom;
@Service
public class SecureRandomServiceImpl implements SecureRandomService {
private SecureRandom secureRandom;
public SecureRandomServiceImpl() {
secureRandom = new SecureRandom();
}
@Override
public Mono<Integer> getRandomInt() {
return Mono.just(secureRandom.nextInt());
}
}
Think for a moment about the getRandomInt() implementation. It’s hard to resist the temptation to wrap anything whatsoever in a publisher. Mono.just(T data) creates a Mono that will emit the specified item. But the item is captured at instantiation time. This will invoke the blocking code at assembly time, perhaps in the context of an event loop thread.
For now, let’s move forward to create the package com.okta.developer.reactive.controller, and add a SecureRandom class for the data:
package com.okta.developer.reactive.controller;
public class SecureRandom {
private String value;
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public SecureRandom(Integer value){
this.value = value.toString();
}
}
Create the SecureRandomController class:
package com.okta.developer.reactive.controller;
import com.okta.developer.reactive.service.SecureRandomService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Mono;
@RestController
public class SecureRandomController {
@Autowired
private SecureRandomService secureRandomService;
@GetMapping("/random")
public Mono<SecureRandom> getSecureRandom(){
return secureRandomService.getRandomInt().map(i -> new SecureRandom(i));
}
}
Add spring-security-test dependency to the pom:
<dependency>
<groupId>org.springframework.security</groupId>
<artifactId>spring-security-test</artifactId>
<scope>test</scope>
</dependency>
Add a SecureRandomControllerTest:
package com.okta.developer.reactive.controller;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.web.reactive.AutoConfigureWebTestClient;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.ActiveProfiles;
import org.springframework.test.web.reactive.server.WebTestClient;
import static org.springframework.security.test.web.reactive.server.SecurityMockServerConfigurers.mockOidcLogin;
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
@AutoConfigureWebTestClient
@ActiveProfiles("test")
public class SecureRandomControllerTest {
@Autowired
private WebTestClient webTestClient;
@Test
public void testGetSecureRandom() {
webTestClient.mutateWith(mockOidcLogin())
.get()
.uri("/random")
.exchange()
.expectStatus().isOk();
}
}
Run with:
./mvnw test -Dtest=SecureRandomControllerTest
The test should pass, but how can you make sure the REST call won’t freeze up the service’s event loop? Use BlockHound!. Blockhound is a Java agent that detects blocking calls from non-blocking threads, has built-in integration with Project Reactor, and supports the JUnit platform.
Add the Blockhound dependency to the pom.xml:
<dependency>
<groupId>io.projectreactor.tools</groupId>
<artifactId>blockhound-junit-platform</artifactId>
<version>1.0.6.RELEASE</version>
<scope>test</scope>
</dependency>
It has been reported that when Spring Security is enabled, BlockHound does not detect blocking calls.
Disable security for the test profile. Add the file src/test/resources/application-test.yml with the following content:
spring:
autoconfigure:
exclude:
- org.springframework.boot.autoconfigure.security.oauth2.client.reactive.ReactiveOAuth2ClientAutoConfiguration
- org.springframework.boot.autoconfigure.security.oauth2.resource.reactive.ReactiveOAuth2ResourceServerAutoConfiguration
- org.springframework.boot.autoconfigure.security.reactive.ReactiveSecurityAutoConfiguration
Rerun the test, and you should see the following error:
reactor.blockhound.BlockingOperationError: Blocking call! java.io.FileInputStream#readBytes
at java.base/java.io.FileInputStream.readBytes(FileInputStream.java) ~[na:na]
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
Error has been observed at the following site(s):
|_ checkpoint ⇢ HTTP GET "/random" [ExceptionHandlingWebHandler]
Stack trace:
at java.base/java.io.FileInputStream.readBytes(FileInputStream.java) ~[na:na]
at java.base/java.io.FileInputStream.read(FileInputStream.java:279) ~[na:na]
at java.base/java.io.FilterInputStream.read(FilterInputStream.java:133) ~[na:na]
at java.base/sun.security.provider.NativePRNG$RandomIO.readFully(NativePRNG.java:424) ~[na:na]
at java.base/sun.security.provider.NativePRNG$RandomIO.ensureBufferValid(NativePRNG.java:526) ~[na:na]
at java.base/sun.security.provider.NativePRNG$RandomIO.implNextBytes(NativePRNG.java:545) ~[na:na]
at java.base/sun.security.provider.NativePRNG.engineNextBytes(NativePRNG.java:220) ~[na:na]
at java.base/java.security.SecureRandom.nextBytes(SecureRandom.java:741) ~[na:na]
at java.base/java.security.SecureRandom.next(SecureRandom.java:798) ~[na:na]
As the log above shows, SecureRandom.next() produces a call to FileInputStream.readBytes(), which is blocking.
The SecureRandomService returns a Mono publisher, but it is an Impostor Reactive Service!
return Mono.just(secureRandom.nextInt());
The implementation above has logic up front, first the calculation secureRandom.nextInt() and then the assembly.
What is the right way to wrap a blocking call? Make the work happen in another scheduler.
Encapsulation of Blocking Calls
Blocking encapsulation needs to happen down into the service, as explained in the Reactor documentation. The scheduler assignment must also happen inside the implementation.
Create the class SecureRandomReactiveImpl.
package com.okta.developer.reactive.service;
import org.springframework.context.annotation.Primary;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Mono;
import reactor.core.scheduler.Schedulers;
import java.security.SecureRandom;
@Service
@Primary
public class SecureRandomReactiveImpl implements SecureRandomService {
private SecureRandom secureRandom;
public SecureRandomReactiveImpl() {
secureRandom = new SecureRandom();
}
@Override
public Mono<Integer> getRandomInt() {
return Mono.fromCallable(secureRandom::nextInt)
.subscribeOn(Schedulers.boundedElastic());
}
}
Run the test again and the BlockHound exception should not happen. Avoid the logic up front and assemble the pipeline. Everything should be fine.
Finally, let’s do an end-to-end test. Run the application with Maven:
./mvnw spring-boot:run
Go to http://localhost:8080/random and you should see the Okta sign in page:
Sign in with your Okta account and you should see a response similar to this:
{
"value": "-611020335"
}
Learn More About Reactive Java
I hope you’ve enjoyed this post. Hopefully, you gained a better understanding of Reactor Schedulers and how to encapsulate blocking code correctly, to avoid freezing the event loop in your Reactive Java application. Some important Reactor topics could not be covered in this post, like error handling, work-stealing and StepVerifier. To continue learning, check out the links below:
- Avoiding Reactor Meltdown
- Secure Reactive Microservices with Spring Cloud Gateway
- Build a Reactive App with Spring Boot and MongoDB
- Reactive Java Microservices with Spring Boot and JHipster
- Reactor 3 Reference Guide
You can find all the code in this tutorial in GitHub.
If you have any questions about this post, please ask in the comments below. For more Spring content, follow @oktadev on Twitter, like us on Facebook, or subscribe to our YouTube channel.
Okta Developer Blog Comment Policy
We welcome relevant and respectful comments. Off-topic comments may be removed.