On this page
OAuth 2.0 and OpenID Connect overview
OAuth 2.0 and OpenID Connect (OIDC) are industry standard protocols for user authentication and authorization. Okta identity solutions are based on these standards.
Learning outcomes
- Learn the difference between OAuth 2.0 and OIDC.
- Learn how to implement flows based on OAuth 2.0 and OIDC using Okta.
- Learn which flows and grant types are commonly used by different types of apps.
Note: To learn about the Okta authentication deployment models built on top of OAuth 2.0 and OIDC, see Okta deployment models.
OAuth 2.0 vs. OpenID Connect
OAuth 2.0 and OpenID Connect (OIDC) are complementary protocols. They define how a server authenticates a user, and then grants the user access to resources.
- OAuth 2.0 (opens new window) controls and delegates authorization to access a protected resource, like your web app, native app, or API service. It provides API security through scoped access tokens.
- OIDC (opens new window) extends OAuth 2.0 with user authentication and Single Sign-On (SSO) functionality. It enables you to retrieve and store authentication information about your end users. It also defines several OAuth 2.0 scopes to enable apps to access user profile information.
Okta recommends using one of its authentication deployment models for your app's authentication needs. Each model abstracts over the OAuth 2.0 and OIDC protocols, so you don't have to use them directly. To get started and to find sample apps, see Sign users in.
Tip: Use the Authentication API if you require a custom app setup and workflow with direct access to your Okta org and app integrations. This API underpins both the Okta redirect model, Embedded Sign-In Widget, and Auth JS SDKs.
OAuth 2.0
OAuth 2.0 is a standard that apps use to provide client apps with access. If you would like to grant access to your app data in a secure way, then you want to use the OAuth 2.0 protocol.
The OAuth 2.0 spec has four important roles:
- Client: The app that wants to access some data.
- Resource server: The API or app that stores the data the client wants to access.
- Resource owner: The owner of the data on the resource server. For example, you're the owner of your Facebook profile.
- Authorization server: The server that manages access and issues access tokens. In this case, Okta is the authorization server.
Other important terms:
- OAuth 2.0 grant: The authorization given (or granted) to the client by the user. Examples of grants are Authorization Code and Client Credentials. Each OAuth grant has a corresponding flow. See Choose an OAuth 2.0 flow.
- access token: The token issued by the authorization server (Okta) in exchange for the grant.
- refresh token: An optional token that is exchanged for a new access token if the access token has expired.
Note: For more information on hard-coded and configurable token lifetimes, see Token lifetime (opens new window).
The following describes the usual OAuth 2.0 Authorization Code flow.
- The client requests authorization from the resource owner (usually the user).
- If the owner gives authorization, the client passes the authorization grant to the authorization server (in this case Okta).
- If the grant is valid, the authorization server returns an access token, possibly alongside a refresh and/or ID token.
- The client now uses that access token to access the resource server.
Note: For a deeper dive into OAuth 2.0, review the What the Heck is OAuth? blog and the OAuth 2.0 spec (opens new window).
At the core of both OAuth 2.0 and OIDC is the authorization server. An authorization server is simply an OAuth 2.0 token minting engine. Each authorization server has a unique issuer URI and its own signing key for tokens to keep a proper boundary between security domains. In the context of this guide, Okta is your authorization server.
The authorization server also acts as an OIDC provider. This means that you can request ID tokens (opens new window) in addition to access tokens (opens new window) from the authorization server endpoints.
Note: For information on authorization servers, how they work, and how you can use them, see Authorization servers.
OpenID Connect
OpenID Connect (OIDC) is an authentication standard built on top of OAuth 2.0. It defines an ID token type to pair with OAuth 2.0 access and refresh tokens. OIDC also standardizes areas that OAuth 2.0 leaves up to choice, such as scopes, endpoint discovery, and the dynamic registration of clients. Okta is OpenID Certified (opens new window).
Although OIDC extends OAuth 2.0, the OIDC specification (opens new window) uses slightly different terms for the roles in the flows:
- OpenID provider: The authorization server that issues the ID token. In this case Okta is the OpenID provider.
- end user: The end user's information that is contained in the ID token.
- relying party: The client app that requests the ID token from Okta.
- ID token: The token issued by the OpenID provider that contains information about the end user in the form of claims.
- claim: The claim is a piece of information about the end user.
The high-level flow looks the same for both OpenID Connect and regular OAuth 2.0 flows. The primary difference is that an OpenID Connect flow results in an ID token, in addition to any access or refresh tokens.
Choose an OAuth 2.0 flow
The OAuth flow that you use depends on your use case. The following sections recommend OAuth 2.0 flows based on:
- The type of app that you're building and the token types that the app requires
- The type of client that you're building
What type of app are you building?
The following table shows you which OAuth 2.0 flow to use for the type of app that you're building.
| Type of app | OAuth 2.0 flow / grant type | Access token? | ID token? |
|---|---|---|---|
| Server-side (aka web), Single-Page Application, or Native | Authorization Code with PKCE or Interaction Code (Identity Engine only). | ✅ | ✅ |
| Trusted | Interaction Code | ✅ | ✅ |
| Service | Client Credentials | ✅ | ❌ |
Note: There's also an OAuth 2.0 SAML 2.0 Assertion flow. This flow is intended for client apps that want to use an existing trust relationship without a direct user approval step at the authorization server. It supports access and ID tokens.
Note: If you're building an integration for the Okta Integration Network (OIN) (opens new window), additional restrictions apply to your flow choice and authorization server. See OIDC/OAuth 2.0 integration limitations.
What kind of client are you building?
The type of OAuth 2.0 flow depends on what kind of client that you're building. This flowchart can quickly help you decide which flow to use.
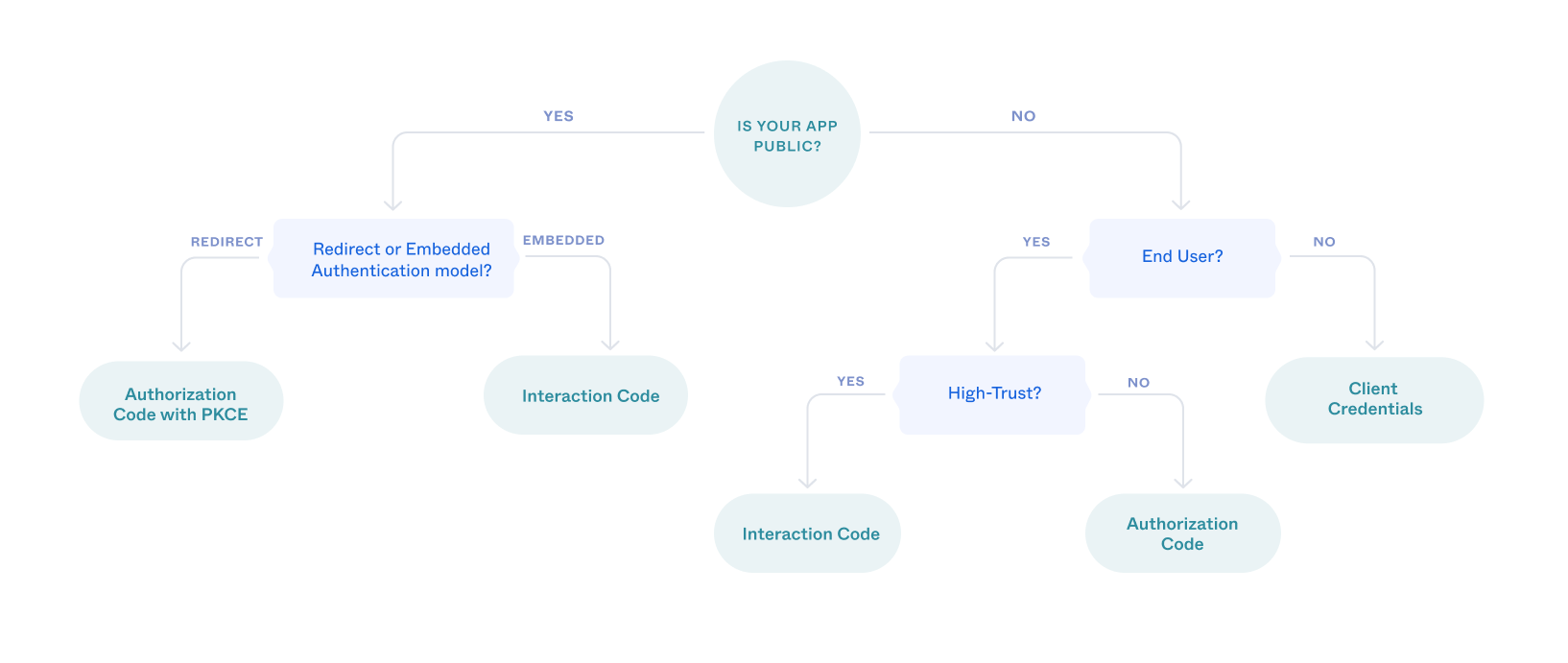
Is your client public?
Single-Page Applications (SPAs), mobile, and native apps are public apps where end users can view and possibly modify the source code of the app. Any secrets in the code are exposed to malicious users. By comparison, server-side (web) and desktop apps are confidential or private apps. Confidential clients can use client-side authentication methods such as client secrets and private keys.
Does your client use the redirect or embedded model?
Note: Okta recommends using redirect authentication in your apps whenever possible. Redirect authentication provides stronger security than the embedded model. See Redirect vs. embedded.
Use the Authorization Code with PKCE flow if your SPA or native app redirects authentication requests to an Okta-hosted sign-in page.
Use the Interaction Code flow if your app hosts the authentication flow itself.
Does the client have an end user?
A client app that runs on a server with no direct end user can be trusted to use its own credentials responsibly. If your client app is only doing machine-to-machine interaction, then you should use the Client Credentials flow.
Is your app high-trust?
An app is high-trust if you own it and the resource that it accesses. Because you own both, you can trust the app to handle your end users' usernames and passwords. In this case, and only if other flows aren't viable, you can use the Resource Owner Password flow. However, it isn't possible to use this flow with multifactor authentication, so consider alternatives such as the Authorization Code or Interaction Code flow.
If your app isn't high-trust, or if you want to take advantage of multifactor authentication, you should use the Authorization Code flow.
Authorization Code flow with PKCE flow
Proof Key for Code Exchange (PKCE) was originally designed as an extension to protect the Authorization Code flow in mobile apps. However, its ability to prevent authorization code injection and keep the flow secure makes it optimal for every type of OAuth client. Okta recommends that you use the Authorization Code flow with PKCE for your OAuth client, if possible.
The flow requires your app to generate a cryptographically random string called a code verifier. The code verifier is then hashed to create the code challenge, and this challenge is passed along with the request for the authorization code. The authorization server responds with an authorization code and associates the code challenge with the authorization code.
After the app receives the authorization code, it sends the authorization code and the code verifier in a request for an access token. The authorization server recomputes the challenge from the verifier using the previously agreed-upon hash algorithm. The authorization server then compares the challenge with the one it associated with the authorization code in the previous step. If the two code challenges and verifier match, the authorization server knows that the same client sent both requests.
Note: For implementing refresh tokens with SPAs and other browser-based apps, see Refresh access tokens.
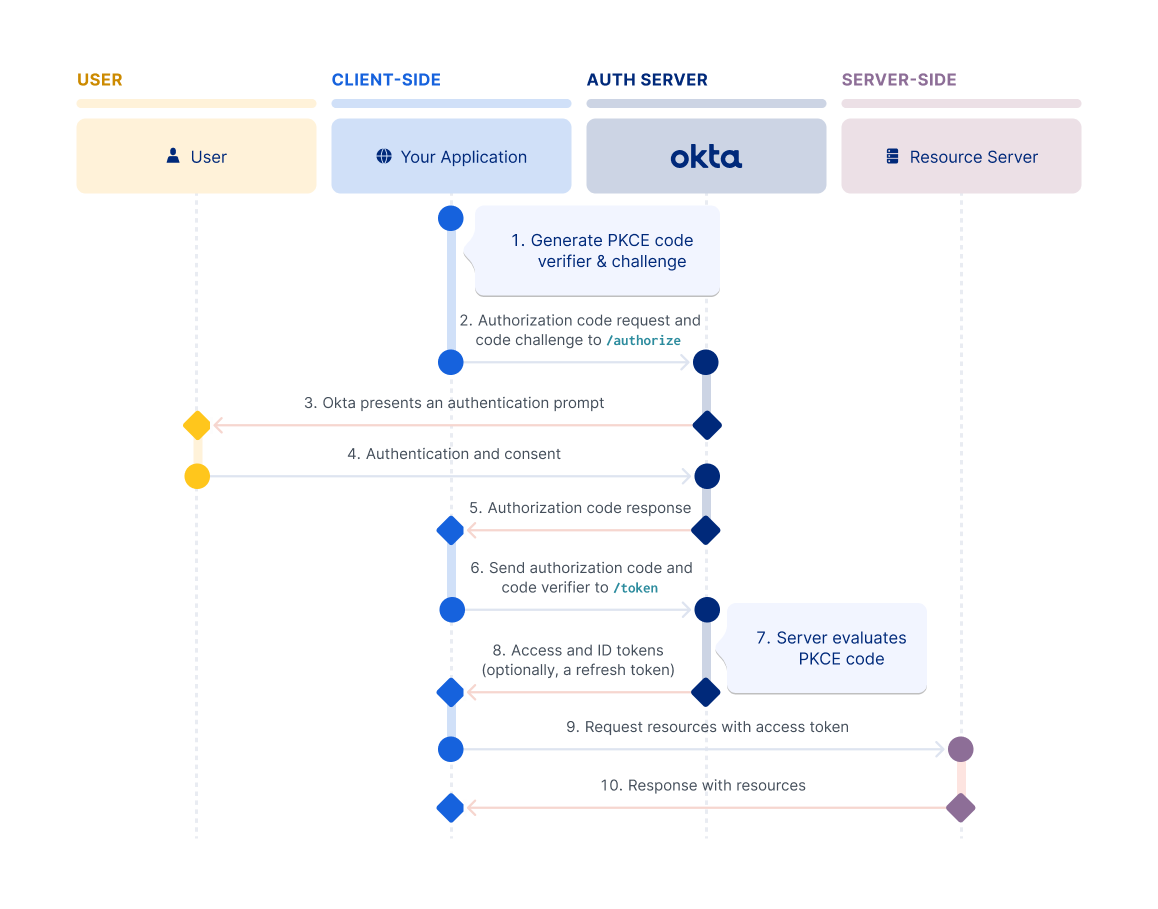
For information on how to set up your app to use this flow, see Implement the Authorization Code flow with PKCE.
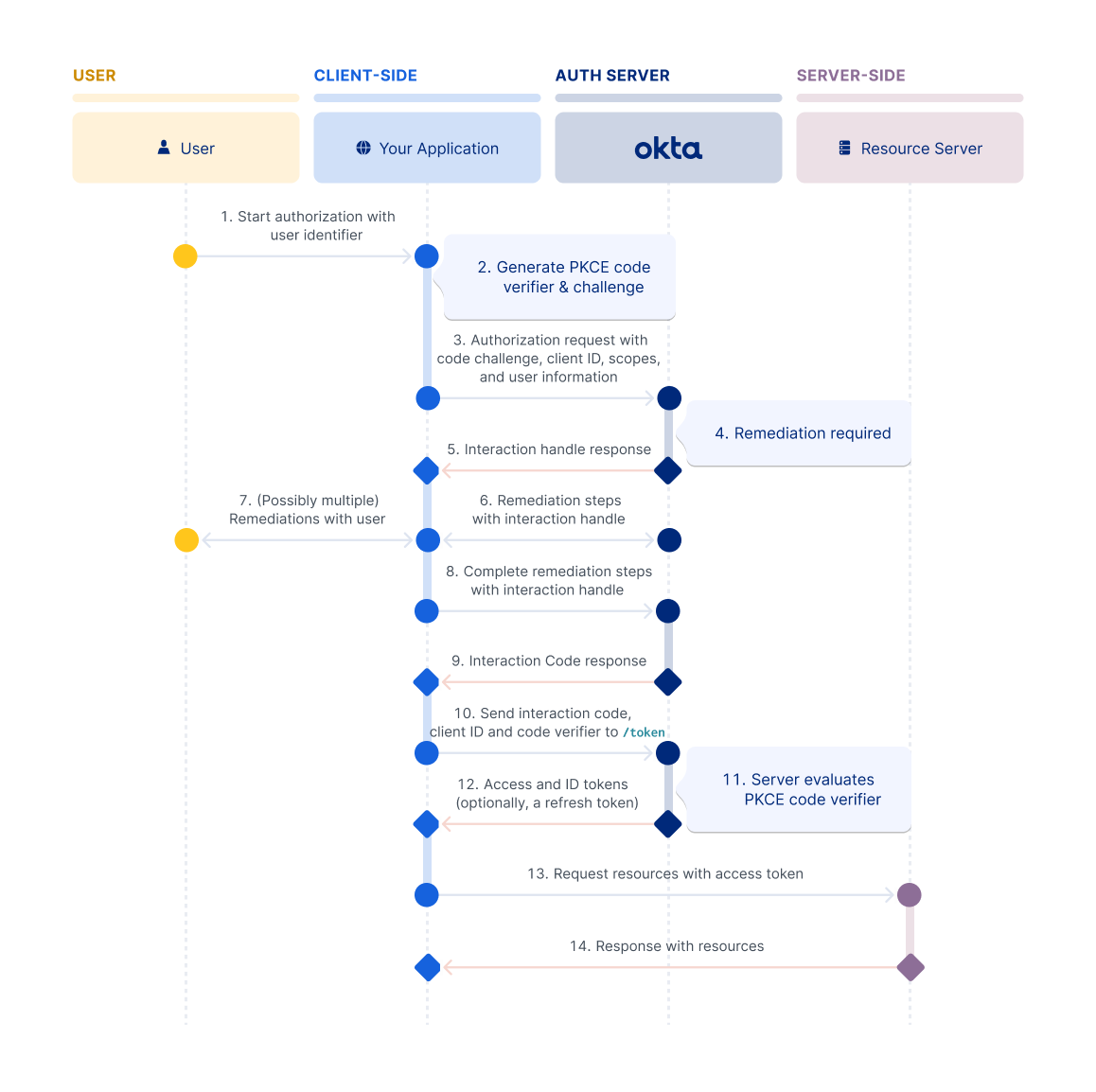
Interaction Code flow
The Interaction Code flow extends the OAuth 2.0 and OIDC standards. It requires clients to pass a client ID and PKCE parameters to Okta to keep the flow secure. The user can start the request with minimal information, relying on the client to facilitate the interactions with Okta to authenticate the user. See Interaction Code grant type.
Note: Interaction Code flow is only available in Identity Engine orgs.
Resource Owner Password flow
The Resource Owner Password flow is intended for use cases where:
- You control both the client app and the resource that it's interacting with.
- The client can store a client secret and can be trusted with the resource owner's credentials.
- You don't need your users to use multifactor authentication.
It's most commonly found in first-party clients made for online services, like the Facebook client apps that interact with the Facebook service. It doesn't require redirects like the Authorization Code or Implicit flows, and involves a single authenticated call to the /token endpoint.
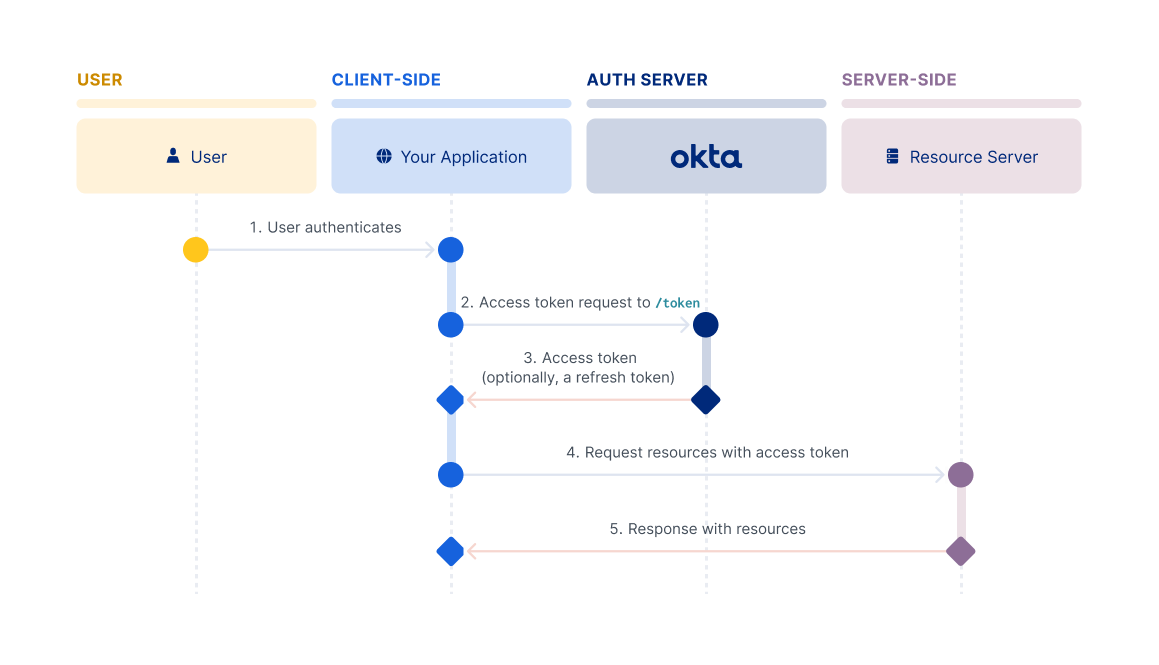
For information on how to set up your app to use this flow, see Implement the Resource Owner Password flow.
Client Credentials flow
The Client Credentials flow is intended for server-side (confidential) client apps with no end user. Normally, this means machine-to-machine communication. The app needs to be server-side because it must be trusted with the client secret. Since the credentials are hard-coded, an actual end user can't use it. It involves a single, authenticated request to the /token endpoint, which returns an access token.
Note: The Client Credentials flow doesn't support refresh tokens.
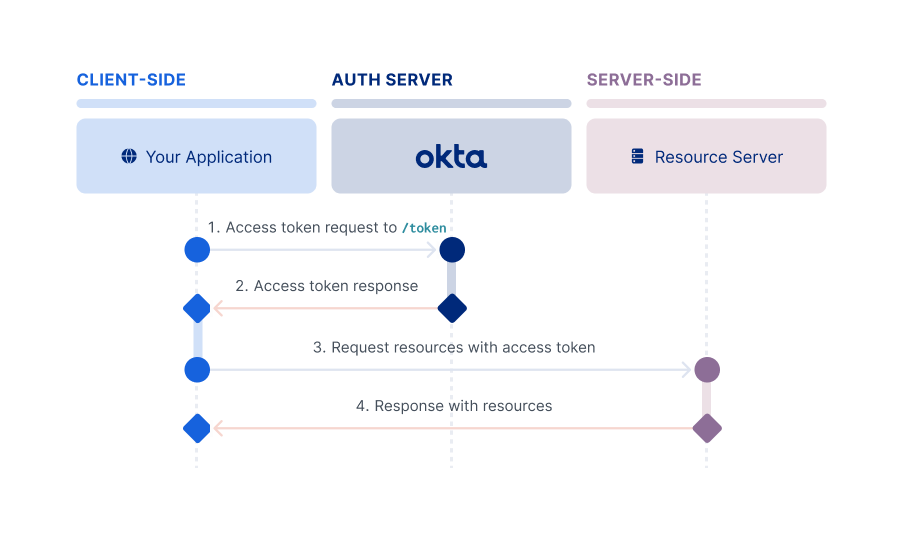
For information on how to set up your app to use this flow, see Implement the Client Credentials flow.
SAML 2.0 Assertion flow
This flow is intended for a client app that uses an existing trust relationship without a direct user approval step at the authorization server. It enables a client app to obtain an authorization from a valid, signed SAML assertion from the SAML Identity Provider. The client app can then exchange it for an OAuth access token from the OAuth authorization server. For example, this flow is useful when you want to fetch data from APIs that only support delegated permissions without prompting the user for credentials.
To use a SAML 2.0 Assertion as an authorization grant, the client makes a SAML request to the Identity Provider. The Identity Provider then sends the SAML 2.0 Assertion back in the response. The client then makes a request for an access token with the urn:ietf:params:oauth:grant-type:saml2-bearer grant type and includes the assertion parameter. The value of the assertion parameter is the SAML 2.0 Assertion that is Base64-encoded. You can send only one SAML assertion in that request.
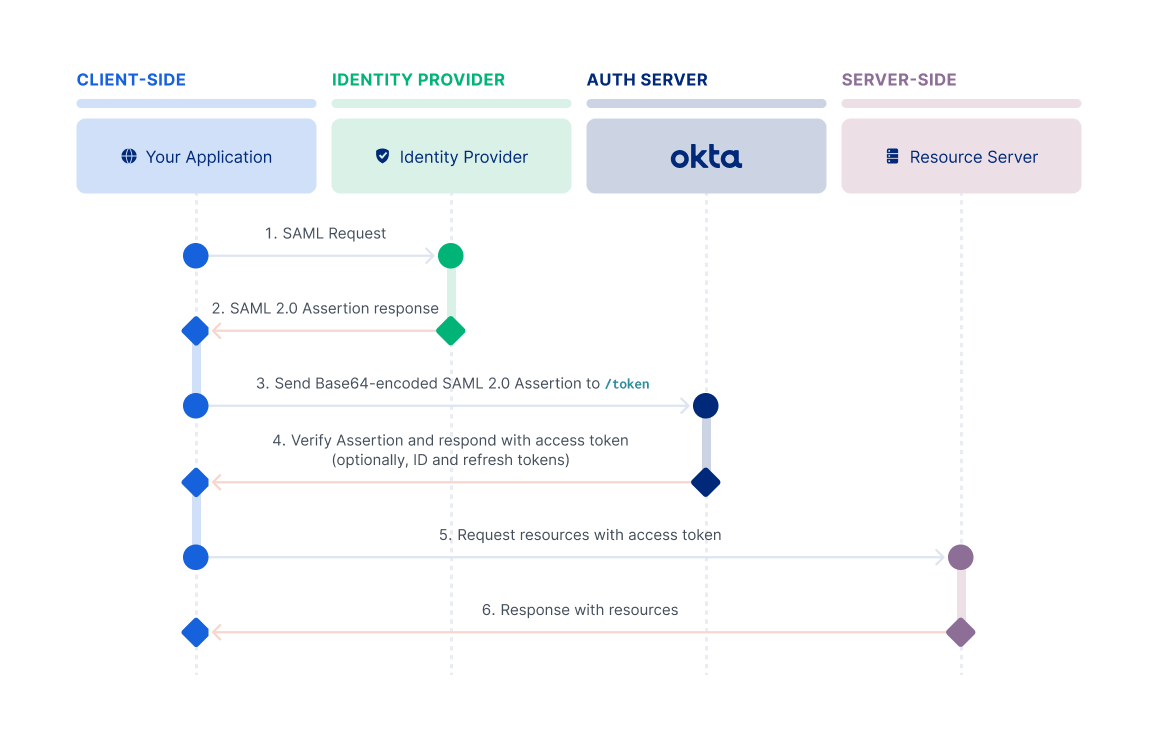
For information on how to set up your app to use this flow, see Implement the SAML 2.0 Assertion flow.
Implicit flow
Note: The Implicit flow is a legacy flow used only for SPAs that can't support PKCE.
The Implicit flow is intended for browser-based apps that don't support Cross-Origin Resource Sharing (CORS). This flow is also intended for browser-based apps that lack modern cryptography APIs, and that can't protect a client secret. In this flow, the client doesn't make a request to the /token endpoint, but instead receives the access token in the redirect from the /authorize endpoint. The client must be able to interact with the resource owner's user agent and to receive incoming requests (through redirection) from the authorization server.
Note: Because it was always intended for less-trusted clients, the Implicit flow doesn't support refresh tokens.
Important: For Single-Page apps (SPA) running in modern browsers that support Web Crypto for PKCE, Okta recommends using the Authorization Code flow with PKCE. Use this flow instead of the Implicit flow for maximum security. If support for older browsers is required, the Implicit flow provides a functional solution.
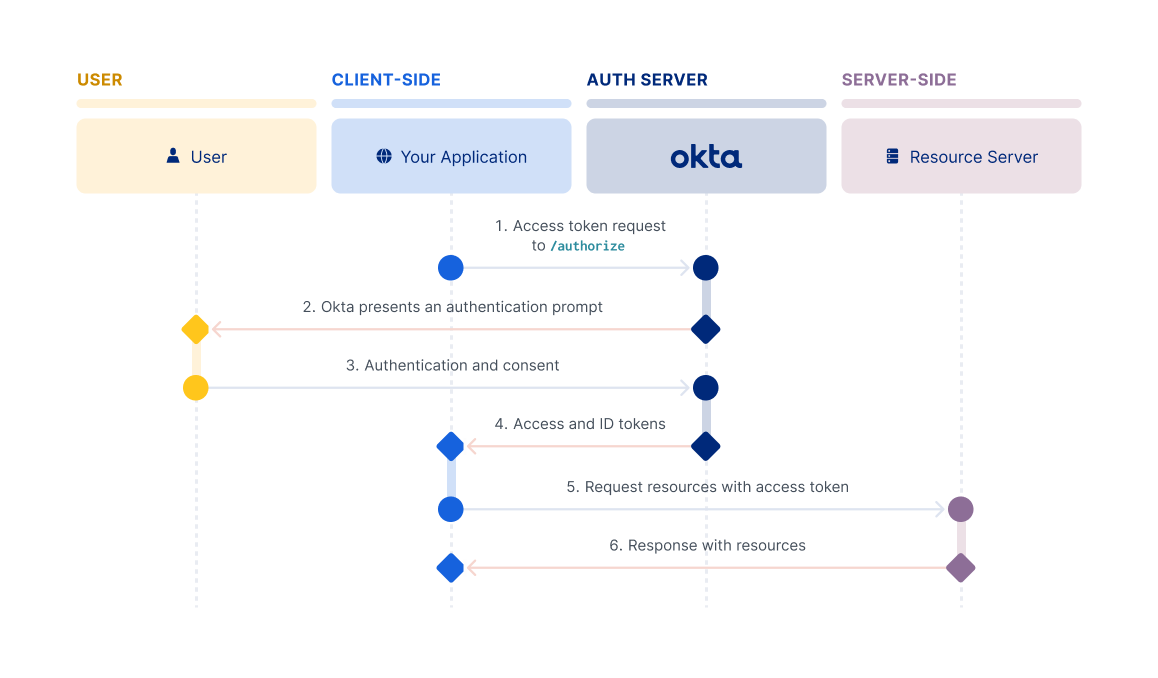
For information on how to set up your app to use this flow, see Implement the Implicit flow.