Okta Software Engineering Design Principles
Okta has been an agile development shop since the beginning. One important aspect of being agile is enabling a mix of bottom-up and top-down decision making. Specifically where high level vision and strategy is clearly communicated enabling teams to autonomously deliver value while also feeding back learnings from the trenches to inform the high level goals.1 Below are the tacit engineering design principles we’ve used to guide development at Okta. They continue to evolve as we experiment and learn.
1. Create User Value
First and foremost, writing software is about creating value for users. This seems straight forward, but as systems evolve and become more complex we start introducing more abstraction and layering which brings us further away from the concrete problem we’re trying to solve. It’s important to keep in mind the reason for writing software in the first place and use the understanding of the audience to inform priority.
At Okta, our entire company is aligned on this principle because our #1 core value is customer success. In practice this means there’s almost always a number of customers eager to beta a new feature we’re working on. We collaborate closely with customers while building features allowing for continuous feedback as we iterate and get changes out in weekly sprints.

2. Keep it Simple
Everything should be made as simple as possible, but no simpler — Albert Einstein
This truism has been around for ages, and it goes hand-in-hand with the first principle. If it doesn’t add value to users now, you ain’t gonna need it - YAGNI!
We all encounter overly complex code where it’s nearly impossible to reason about what it does. Part of this confusion is because it’s generally harder to read code than to write it but beyond that, there are clearly fundamental qualities of some code making it more intuitive than other code. There’s a lot of prior art on this topic and a great place to start is Clean Code by Robert C. Martin, aka Uncle Bob. The book breaks down the qualities of code which make it intuitive, and provides a framework for reasoning about code quality.
Here are some guiding principles about writing clean code we use in practice which are also covered in the book.
Clean code:
- Makes intent clear, use comments when code isn’t expressive enough
- Can be read and enhanced by others (or the author after a few years)
- Provides one way, rather than many, to do a particular task
- Is idomatic
- Is broken into pieces which each does one thing and does it well
At the end of the day there is no substitue for experience, like any craft, writing clean code takes practice. At Okta every engineer is constantly honing their skills, we rely heavily on code reviews and pair programming to help hone each other’s skills.

3. Know Thy-Service With Data
In the world of “big data” this point needs little explanation. Okta collects massive amounts of operational data about our systems to:
- Monitor health
- Monitor performance
- Debug issues
- Audit security
- Make decisions
With every new feature we add, developers are responsible for ensuring that their designs provide visibility into these dimensions. In order to make this an efficient process we’ve invested in:
- Runtime logging control toggling by level, class, tenant, user
- Creation of dashboards and alerts is self-service
- Every developer has access to metrics and anonymous unstructured data
- Request ID generated at edge is passed along at every layer of stack for correlation
- Engineering control panel for common operational tasks like taking threaddumps
Technologies we use to gain visibility include: PagerDuty, RedShift, Zabbix, ThousandEyes, Boundary, Pingdom, App Dynamics, Splunk, ELK, S3.
4. Make Failure Cheap
Every software system will experience failures and all code has bugs. While we constantly work at having fewer, it’s unrealistic to assume they won’t occur. So, in addition to investing in prevention, we invest in making failure cheap.
The cost of failure becomes significantly more expensive further out on the development timeline. Making adjustments during requirements gather and design are significantly cheaper than finding issues in production.2
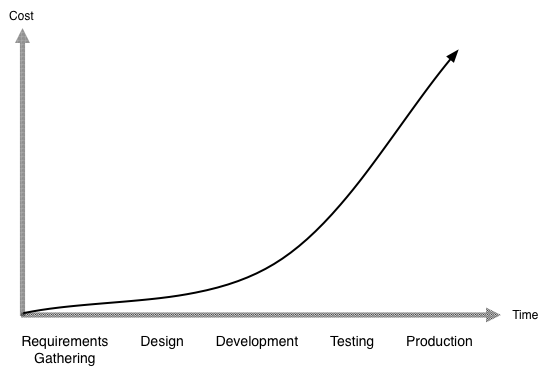
One fundamental we take from both Agile and XP is to invest in pushing failure as early in the development timeline as possible. We mitigate failures from poor requirements gathering by iterating quickly with the customer as described in Principle 1. Once we get to design and development we make failure cheap through:
- Design reviews with stakeholders ahead of writing code
- TDD - developers write all tests for their code; test isn’t a separate phase from development
- Keeping master stable - check-in to master is gated by passing all unit, functional and UI tests
- Developers can trigger CI on any topic branch; CI is massively parallelized over a cloud of fast machines
Since our testing phase is done during development the next phase is production deployments. At this phase we reduce the cost of failure by:
- Hiding beta features behind flags in the code
- Incremental rollout first to test accounts and then in batches of customers
- Automated deployment process
- Code and infrastructure is forwards and backwards compatible allowing rollback
- Health check and automatically remove down nodes
- Return a degraded / read-only response over nothing at all
An escalator can never break; it can only become stairs – Mitch Hedberg
5. Automate Everything
All tasks performed routinely should be automated. These are automation principles we follow:
- Automate every aspect of the deployment including long running db migrations
- All artifacts are immutable and versioned
- All code modules get dependencies automatically from central artifact server
- Creation of base images and provisioning of new hardware is automated
- All forms of testing are automated
- Development environment setup is automated
Tools we use:
- AWS - Automated provisioning of hardware
- Chef - Configuration managment
- Ansible - Automated deployment orchestration
- Jenkins - Continuous integration
- Gearman - To get Jenkins to scale
- Docker - Containerizing services
6. With Performance, Less is More
We find especially with performance, there are typically huge wins to be had in up front design decisions which may come at very little to no cost. Our design mantras for performance are:
- Don’t do it
- Do it, but don’t do it again
- Do it less
- Do it later
- Do it when they’re not looking
- Do it concurrently
- Do it cheaper
In practice we implement a number of strategies to limit risk to poorly performing code:
- Major new features and performance tunings live behind feature flags allowing slow rollout and tuning in real life environment
- Chunk everything that scales on order of N. When N is controlled by customer enforce limits and design for infinity.
- Slow query and frequent query monitoring to detect poor access patterns

Reference
-
Ikujiro Nonaka, and Hirotaka Takeuchi. The Knowledge Creating Company. Oxford University Press, 1995. Print. ↩
-
Scott Ambler. Examining the Agile Cost of Change Curve. ↩
Okta Developer Blog Comment Policy
We welcome relevant and respectful comments. Off-topic comments may be removed.