Productionalizing ActiveMQ
This post describes our odyssey with ActiveMQ, an open-source version of the Java Messaging Service (JMS) API. We use ActiveMQ as the message broker among our app servers.
First, a word of thanks. To overcome the challenges we faced with ActiveMQ, we are greatly indebted to a very thorough description of an OpenJDK bug, as well as some other online resources. If you’re having problems with ActiveMQ, read on. Maybe our story can help you.
Growing Pains
Our problems with ActiveMQ date all the way back to 2012. They centered around high memory and CPU usage, message timeout errors, and message queue delays.
Let’s pick up the action in the spring 2014. At that time we were battling a new wave of timeout storms and message queue delays caused by our mixed ActiveMQ configuration (broker 5.4.1, client 5.7) and increasing traffic on our site.
Of course we welcomed the growth in traffic as a byproduct of our growing business. And although we did plan to address our mixed ActiveMQ configuration, we decided to delay doing so at that time, opting instead to tune the configuration. So we increased the maximum session size from 500 to 2000, and the page size from 200 to 2000 messages. Increasing the page size served to minimize “hung queue” scenarios — a side effect of using message selectors.
Another Inflection Point
Business and site traffic continued to grow, contributing to another inflection point in the fall of 2014. Timeout storms, CPU spikes, and memory issues returned. It was clear that we could no longer put off upgrading to a newer version of ActiveMQ.
We decided to skip versions 5.7 and 5.8 in favor of 5.10, mainly because 5.7 was considered unstable, and 5.10 provided improved failover performance.
Would this upgrade finally deliver the stability that had eluded us for so long?
When Upgrades Bite Back
Unfortunately, no. Within 24 hours, memory usage soared, CPUs spiked, and instability returned. Note the dramatic CPU spikes in the following screenshot.
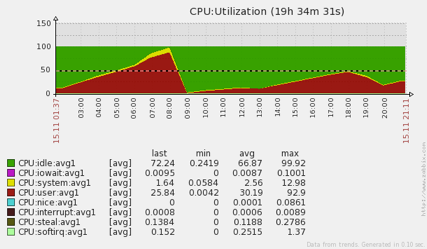
To prevent these issues from impacting customers, we were forced to restart brokers, which is always an option of last resort. Restarting brokers is a delicate operation, which can entail a less-than-smooth failover, risking message loss.
We immediately increased memory, but within a day or two we ran out of memory again.
Searching for the Root Cause
An online search turned up an OpenJDK bug that identified an out of memory issue in the ConcurrentLinkedQueue, which is a class in the java.util.concurrent package included in JVM version 1.6. When working properly, ConcurrentLinkedQueue allows elements to be added and removed from the queue in a thread-safe manner.
The bug caused a null object to be created whenever an element at the end of the queue was added and then deleted. This behavior is particularly unfavorable to the way we use queuing. We call ActiveMQ to create and destroy objects in the queue very quickly, tens of millions of times a day, as users and agents connect to Okta. As a result, null objects rapidly fill up the queue, memory usage soars, and CPUs spike.
Conference Call
With the site at risk of impacting customer authentication, several key engineers, including Hector Aguilar, Okta’s CTO and SVP of Engineering, met on a Saturday afternoon conference call. Discussion was intense, and our options were few and unappealing: (a) revert all the way back to broker version 5.4.1, or (b) upgrade to broker version 5.11, which was still unreleased and might introduce new problems.
As team members recall, Hector said very little during the first half of the meeting.
A bug in the JVM surprised Hector, as critical JVM bugs are relatively rare. Fortunately, the OpenJDK bug we’d found included a very thorough description of the problem, as well as sample code to reproduce it.
Initially motivated by curiosity, Hector analyzed the code and the bug description. He saw where the problem was, and then checked online to see if it had been fixed in newer JDK versions. He noticed that several things were changing in the class, and that others had attempted to resolve the bug in different ways, but none that would solve our particular problem. Hector developed a very simple fix of his own, trying to remain consistent with the work of others. He then verified his fix using the provided sample code.
The JVM has a mechanism called endorsed libraries that allows developers to override an existing class with a new class, effectively patching the JVM. Hector used this mechanism, packaged his fix into a jar file, tried it against ActiveMQ, and found that it worked.
The mood and direction of the meeting shifted dramatically when Hector said, “Guys, I have a wild idea. What if we patch the JVM?” As none of us had ever patched a JVM before, this seemed like a novel approach, even a long shot.
The Fix
Hector sent his JVM patch and sample code to the team and walked us through it. First, he explained why the other attempted fixes wouldn’t solve our particular problem. He then demonstrated how his override effectively patched the original (faulty) removal method. Members of the team volunteered to test the override at scale with our simulated environments. Within a few hours, we were fairly sure that Hector’s fix would work.
Deploying the Patch
We deployed the patch and restarted brokers. It was a success! ActiveMQ no longer ran out of memory and the CPU spikes ceased.
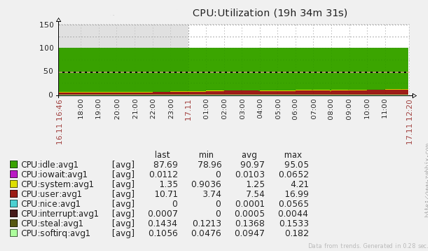
Some minor memory leaks remained, but these were eliminated by upgrading to java-1.7.0.
Stable, and looking at other solutions
Patching the ConcurrentLinkedQueue with ActiveMQ v5.10 and upgrading to java-1.7.0 provided acceptable stability and faster failover performance. While this is a significant improvement over where we were last fall, our goal is zero failover time, which ActiveMQ cannot deliver. So, we’re exploring other messaging solutions.
In telling our story, we couldn’t resist tooting our own horn a bit. How many CTOs actually get their hands dirty tackling product issues? Our CTO doesn’t code very often, but when he does, he patches the JVM.
Okta Developer Blog Comment Policy
We welcome relevant and respectful comments. Off-topic comments may be removed.